顺序消息在开发中有发挥着重要的的作用,尤其是在涉及多个步骤的业务流程中,是保证系统稳定、数据一致和业务逻辑正确性的重要手段。
为什么需要顺序消息?
顺序消息确保系统的执行按照预定的流程进行,是保证系统稳定、数据一致和业务逻辑正确性的重要手段。如下图:
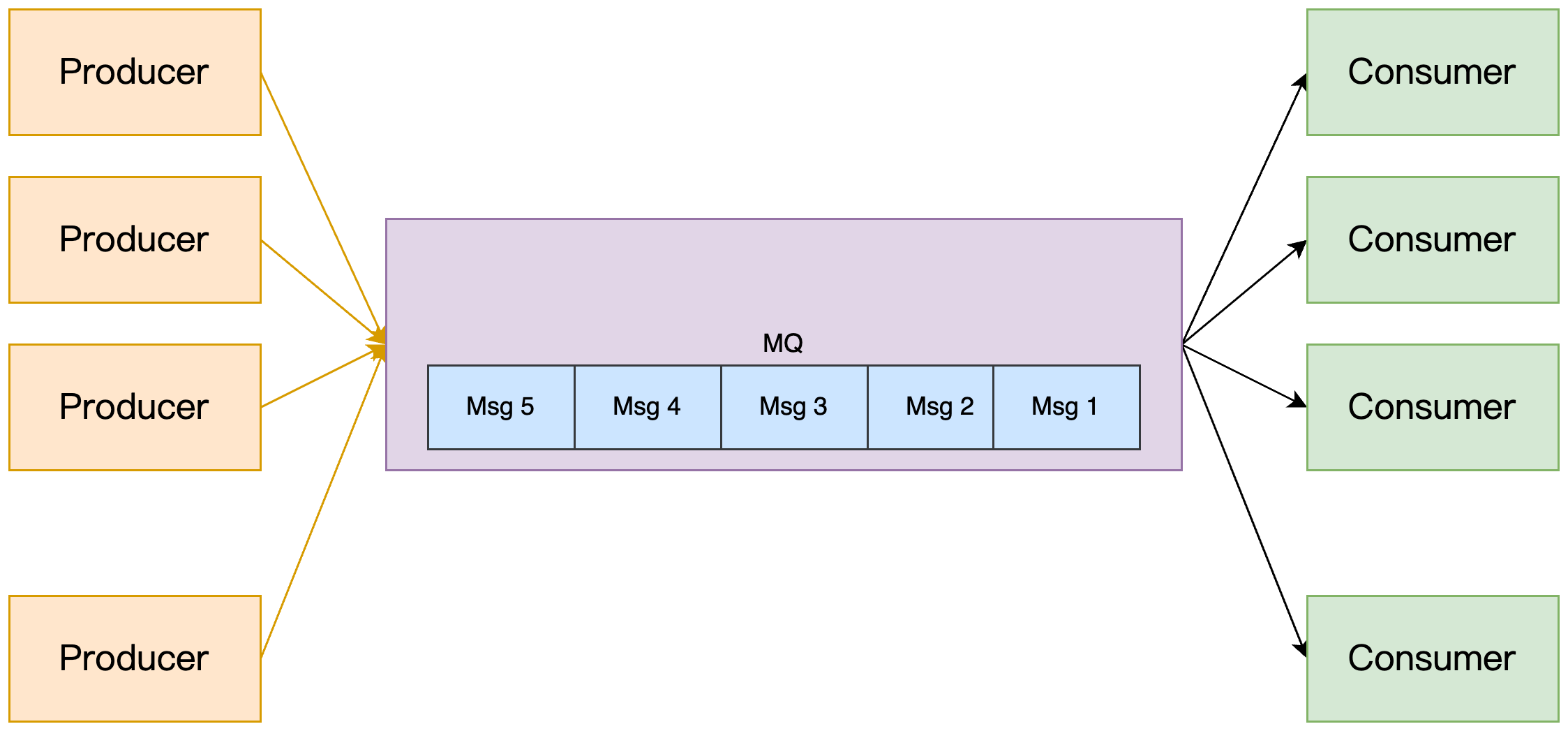
比如生产者是 Msg1,Msg2, Msg3,Msg4,Msg5 的顺序发出,消息的接受者也要按这个顺序进行消费,系统间需要维持强一致的状态同步,上游的事件变更需要按照顺序传递到下游进行处理。以一个实际的业务场景为例:
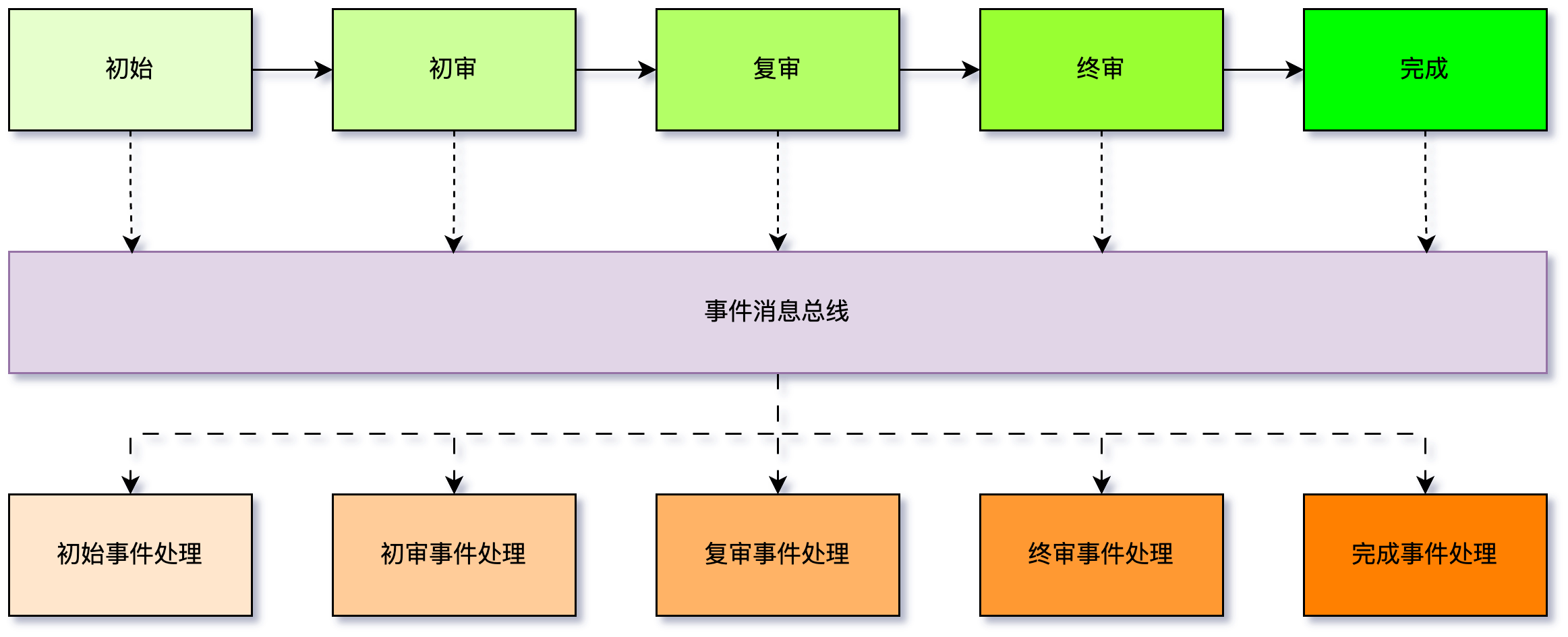
在审批系统中,通常有多个审批节点,像是初审、复审、终审等。每一层的审批都依赖于上一层的审批结果。例如,只有初审通过,复审才会进行;复审通过后,才能进入终审。每一层的审批结果是后续流程的输入,所有的审批必须按照正确的顺序来进行。并且系统采用事件驱动架构,每次操作都链接一个事件消息总线,操作完成后发送消息,事件处理模块收到消息后对各种消息进行处理。这样的场景就十分依赖事件消息的顺序性,如果复审的消息比初审更先到达,这就出现业务不一致的情况。
RocketMQ 顺序消息
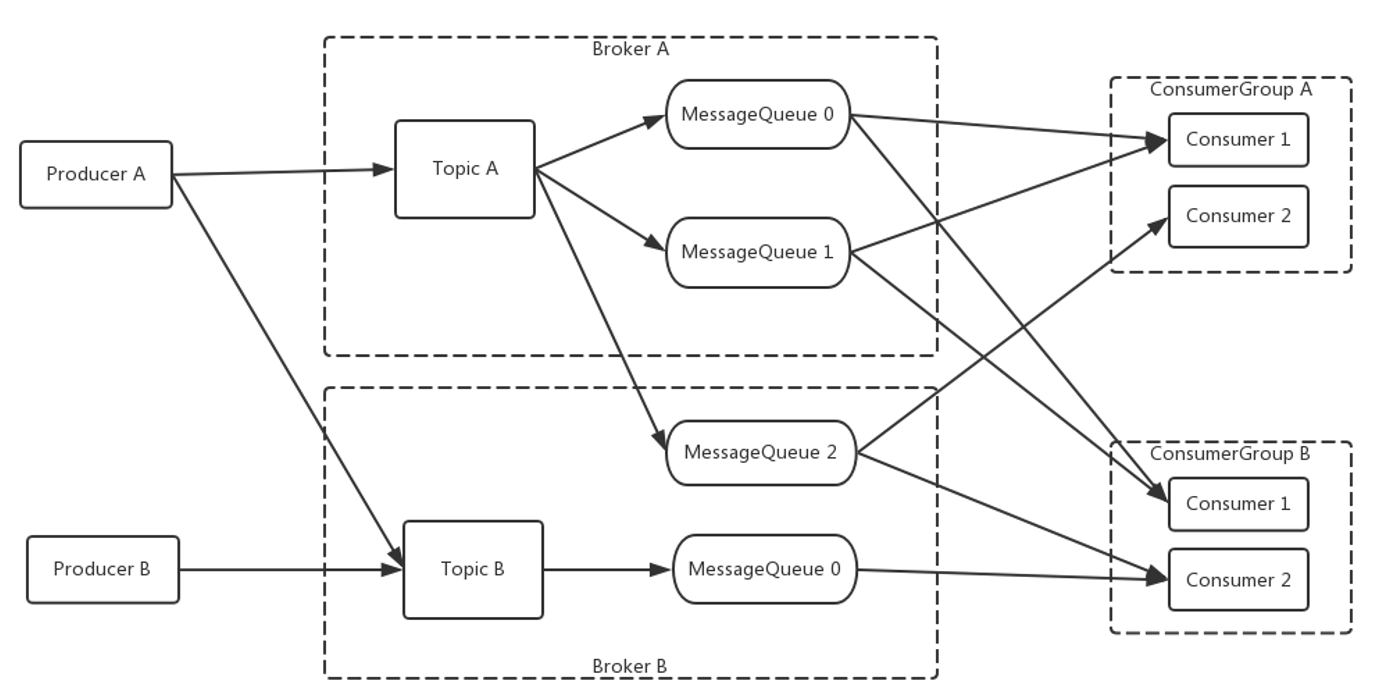
RocketMQ 里的分区队列 MessageQueue 本身是能保证 FIFO 的,RocketMQ Topic 架构如下(图源 Rocket MQ 官方文档):
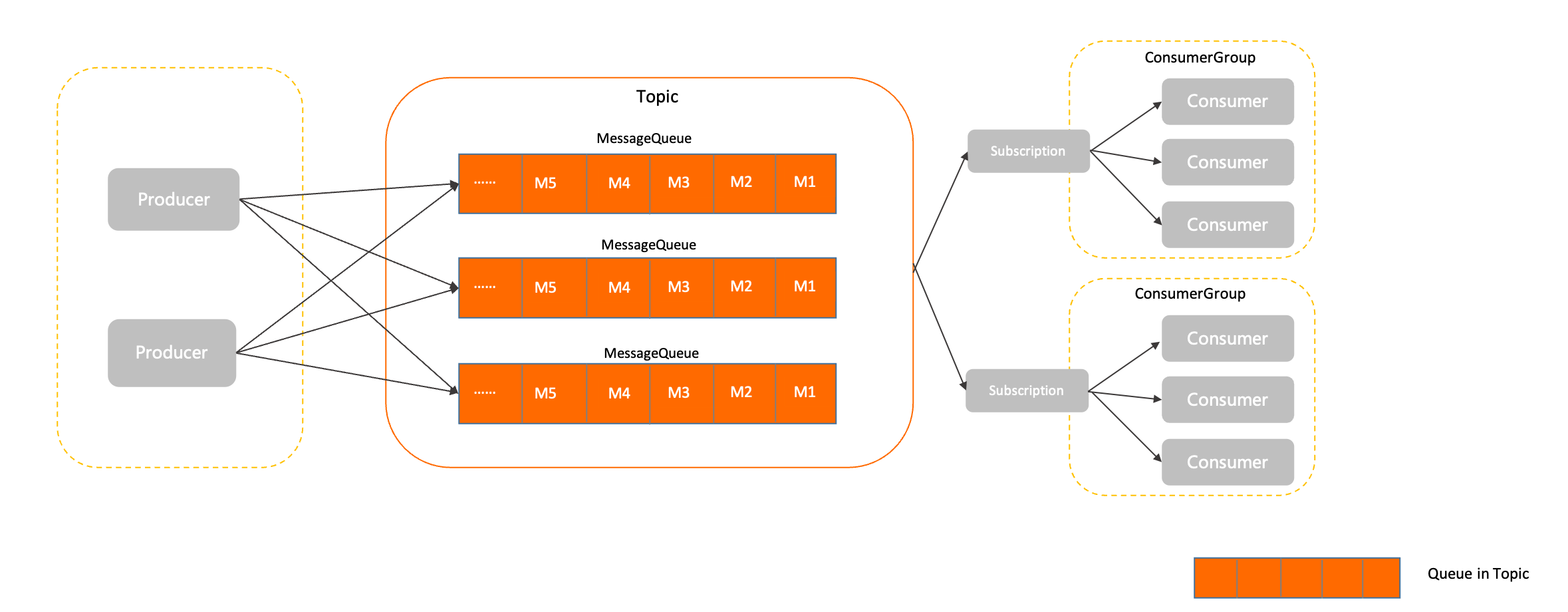
正常情况下不能顺序消费消息主要有两个原因:
- Producer 发送消息到 MessageQueue 时是轮询发送的,消息被发送到不同的分区队列,就不能保证 FIFO了。
- Consumer 默认是多线程并发消费同一个 MessageQueue 的,即使消息是顺序到达的,也不能保证消息顺序消费。
设置队列数量
开发版 RocketMQ 设置队列大小:
public class AsyncProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("producer_A");
// NameServer
producer.setNamesrvAddr("localhost:9876");
// 指定异步发送失败后不进行重试发送
producer.setRetryTimesWhenSendAsyncFailed(0);
// 指定新创建的Topic的Queue数量为2,默认为4
producer.setDefaultTopicQueueNums(2);
// 开启生产者
producer.start();
// 模拟发送100条消息
for (int i = 0; i < 100; i++) {
byte[] bytes = ("hi " + i).getBytes();
try {
Message msg = new Message("topic_A", "tag_A", bytes);
// 异步发送,指定回调
producer.send(msg, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
System.out.println(sendResult);
}
@Override
public void onException(Throwable throwable) {
throwable.printStackTrace();
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
// 异步发送,如果不执行sleep,则消息在发送之前,producer已经关闭,就会报错
TimeUnit.SECONDS.sleep(3);
// 关闭生产者
producer.shutdown();
}
}
商用版 RocketMQ 设置队列大小(火山引擎文档):
消息发向 RocketMQ 时,发向的是 Broker 內的多个 Queue,消息消费时,会根据特定算法在某一个 Queue 中消费,所以在消费时,无法保证顺序性,只能在单 Queue 中有序,也就是“局部有序”,想要做到全局有序,只能将这个 Topic 的 Queue 队列数为 1,“局部”变全局。
在生产环境中,消息队列的队列数一般是由运维控制,不建议频繁修改。
RocketMQ 架构借鉴自 Kafka,RocketMQ 队列模型和Kafka的分区(Partition)模型类似,所以 Kafka实现顺序消息也跟 RocketMQ 类似。
加锁
RocketMQ 的 Queue 设计之初是为了提高并发度而设计,如果一个 Topic 只有一个队列,无疑对消息队列的高并发是一个极大的削弱,那么有没有其他方法实现顺序消息,使用多个队列且能够并发消费呢?另一种方式有一种方式就是加锁。Rocket MQ就是这个做的,在Consumer 加本地锁,在 Broker 加全局锁,实现顺序消费。加锁代码如下(Github):
public boolean lock(final MessageQueue mq) {
FindBrokerResult findBrokerResult = this.mQClientFactory.findBrokerAddressInSubscribe(this.mQClientFactory.getBrokerNameFromMessageQueue(mq), MixAll.MASTER_ID, true);
if (findBrokerResult != null) {
LockBatchRequestBody requestBody = new LockBatchRequestBody();
requestBody.setConsumerGroup(this.consumerGroup);
requestBody.setClientId(this.mQClientFactory.getClientId());
requestBody.getMqSet().add(mq);
try {
Set<MessageQueue> lockedMq =
this.mQClientFactory.getMQClientAPIImpl().lockBatchMQ(findBrokerResult.getBrokerAddr(), requestBody, 1000);
for (MessageQueue mmqq : lockedMq) {
ProcessQueue processQueue = this.processQueueTable.get(mmqq);
if (processQueue != null) {
processQueue.setLocked(true);
processQueue.setLastLockTimestamp(System.currentTimeMillis());
}
}
boolean lockOK = lockedMq.contains(mq);
log.info("message queue lock {}, {} {}", lockOK ? "OK" : "Failed", this.consumerGroup, mq);
return lockOK;
} catch (Exception e) {
log.error("lockBatchMQ exception, " + mq, e);
}
}
return false;
}
public void consumeMessageDirectly(final List<MessageExt> msgs, final String consumerGroup,
final ConsumeOrderlyContext context) {
if (msgs == null || msgs.isEmpty()) {
return;
}
final MessageListenerOrderly listener = this.consumeOrderlyDispatch.get(consumerGroup);
if (listener == null) {
log.warn("consumeMessageDirectly: {}, the consumer group: {} not exist!", RemotingHelper.parseChannelRemoteAddr(ctx.channel()), consumerGroup);
return;
}
for (MessageExt msg : msgs) {
try {
// 调用消费者处理消息
final ConsumeOrderlyStatus status = listener.consumeMessage(Collections.singletonList(msg), context);
if (null == status) {
throw new MQClientException("Return value of the listener cannot be null", null);
}
switch (status) {
case SUCCESS:
break;
case SUSPEND_CURRENT_QUEUE_A_MOMENT:
// 暂停当前队列一段时间,以便其他队列的消息得到消费
context.setSuspendCurrentQueueTimeMillis(listener.suspendCurrentQueueTimeMillis());
break;
default:
throw new MQClientException("Illegal consume orderly status", null);
}
} catch (Throwable e) {
log.warn("consumeMessageDirectly exception", e);
}
}
}
Redis 顺序消息
单 Queue 消费与加锁也会影响性能,有没有其他方法实现顺序消息呢?在 MQ 领域目前没有好方法,现在流传一种轻量级实现方案——Redis 消息队列,搜索结果如下:
Redis 确实可以实现轻量级的消息队列,但是这种实现,会有两个缺点:
- Redis 本身定位是内存数据库,它的设计之初都是为缓存准备的,并不具备消息堆积的能力。而专业消息队列一个非常重要的功能是数据中转枢纽,Redis 的定位很难满足,所以使用起来要非常小心。
- Redis 的高可用方案可能丢失消息(AOF 持久化 和 主从复制都是异步 ),而专业消息队列可以针对不同的场景选择不同的高可用策略。
Redis 的并发与持久化
的确,Redis 无法取代那些老牌消息队列,但是他有一个核心优势——Redis 的单线程命令执行,天然保证了 Redis 的并发安全。
Redis 的持久化依靠 RDB 与 AOF 两种机制,RDB 会在指定的时间间隔内创建数据的快照(dump)。AOF 通过将写命令追加到日志文件中来持久化数据。RDB + AOF 可以保证 Redis 数据不丢失,AOF 配置 appendfsync 参数用于设置“真正执行”操作命令向 AOF 文件中同步的策略。
# 同步策略
# appendfsync always
appendfsync everysec
# appendfsync no
使用同步策略可以避免一些操作系统,机房故障,但是遇到磁盘损坏时,就需要使用Redis的高可用方案了,这又是另一个话题。
使用 Redis 实现顺序消息,是不是一种好的选择?
Redis 的 Stream
Redis List 数据结构用做队列时,因为消费时没有 Ack 机制,应用异常挂掉导致消息偶发丢失的情况,Redis Stream 从设计角度来讲已经完美的解决了。Redis 的 Stream 是在 5.0 版本先加入的数据结构,其工作模式如下:
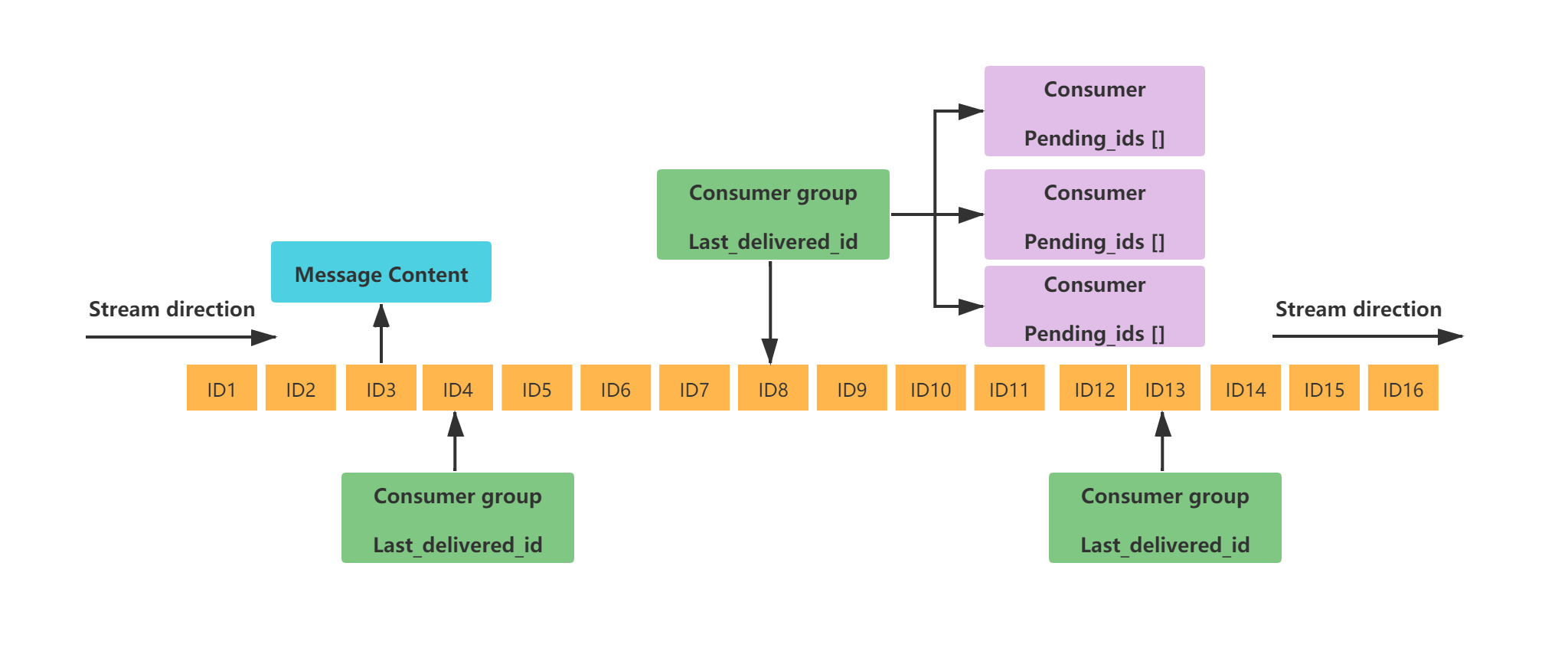
每个 Redis Streamt 都有唯一的名称 ,对应唯一的 Redis Key 。
-
同一个 Stream 可以挂载多个消费组 ConsumerGroup , 消费组不能自动创建,需要使用 XGROUP CREATE 命令创建。Der
-
每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动 ,标识当前消费组消费到哪条消息了。
-
消费组 ConsumerGroup 同样可以挂载多个消费者 Consumer , 每个 Consumer 并行的读取消息,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
-
消费者内部有一个属性 pending_ids , 记录了当前消费者读取但没有回复 ACK 的消息 ID 列表 。当消费者重新上线,这些消息可以重新被消费。
Redis 的 Stream 这种数据结构,十分适合做消息队列。在 Redis 中 Stream 类似于 MQ 的 Topic ,每个 Stream 只有一个队列,也就没有 MQ 中的多队列并发消费问题。接下来实现消息队列的核心功能
创建 Stream 组
@PostConstruct
public void createConsumerGroup() {
log.info("createConsumerGroup...");
try {
// 如果消费组不存在,则创建
stringRedisTemplate.opsForStream().createGroup(STREAM_NAME, GROUP_NAME);
} catch (Exception e) {
// 如果消费组已存在,忽略错误
if (!e.getMessage().contains("BUSYGROUP")) {
throw e;
}
}
}
Stream 消息发送
@GetMapping("/stream")
public ResponseEntity<User> stream(String key, String value) {
Map<String, String> map = new HashMap<>();
map.put(key, value);
Record<String, Map<String, String>> record = StreamRecords.newRecord().ofMap(map).withStreamKey("CommonKey").withId(RecordId.autoGenerate());
RecordId recordId = stringRedisTemplate.opsForStream()
.add(record);
return null;
}
Stream 消息监听
实现 StreamListener 接口的 onMessage 方法,这个方法会执行监听消息后的处理逻辑。
class MyStreamListener implements StreamListener<String, MapRecord<String, String, String>> {
@Override
public void onMessage(MapRecord<String, String, String> entries) {
RecordId id = onProcess(entries);
ack(id.getValue());
}
}
将 Subscription 注入到 Spring:
@Bean
public Subscription subscription(RedisConnectionFactory redisConnectionFactory) {
StreamOperations<String, Object, Object> streamOps = stringRedisTemplate.opsForStream();
//监听容器配置
StreamMessageListenerContainer.StreamMessageListenerContainerOptions<String, MapRecord<String, String, String>> options = StreamMessageListenerContainer
.StreamMessageListenerContainerOptions
.builder()
.pollTimeout(Duration.ofSeconds(1))
.build();
//监听器实现
MyStreamListener streamListener = new MyStreamListener();
//创建监听容器
StreamMessageListenerContainer<String, MapRecord<String, String, String>> listenerContainer = StreamMessageListenerContainer.create(redisConnectionFactory, options);
//groupName需要提前创建
Subscription subscription = listenerContainer.receiveAutoAck(Consumer.from(GROUP_NAME, CONSUMER_NAME),
StreamOffset.create(STREAM_NAME, ReadOffset.lastConsumed()),
streamListener);
listenerContainer.start();
log.info("--------------------stream 监听启动------------------------------");
return subscription;
}
Stream 消息处理
private static RecordId onProcess(MapRecord entries) {
log.info("MapRecord = {}", entries);
return entries.getId();
}
Stream 消息 ACK
/**
* ACK 消息
*/
private void ack(String id) {
stringRedisTemplate.opsForStream().acknowledge(STREAM_NAME, GROUP_NAME, id);
}
Stream 消费异常消息
当有些消息因为某些原因没有 ACK 时,会将消息存在 Pendding 里,需要重新获取再消费。
public void processPendingMessages(StreamOperations<String, Object, Object> streamOps) {
log.info("processPendingMessages...");
PendingMessages pendingMessages = streamOps.pending(
STREAM_NAME, Consumer.from(GROUP_NAME, CONSUMER_NAME));
Iterator<PendingMessage> iterator = pendingMessages.stream().iterator();
while (iterator.hasNext()) {
PendingMessage pendingMessage = iterator.next();
String messageId = pendingMessage.getId().getValue();
String consumer = pendingMessage.getConsumer().getName();
if (!consumer.equals(CONSUMER_NAME)) {
log.info("PendingMessage consumer: {}", consumer);
continue;
}
// 处理每个 Pending 消息
List<MapRecord<String, Object, Object>> records = stringRedisTemplate.opsForStream().range(
STREAM_NAME, Range.just(messageId)
);
if (!records.isEmpty()) {
MapRecord<String, Object, Object> record = records.get(0);
onProcess(record);
}
ack(messageId);
}
}
Stream 消费离线消息
在消息生产时,且消费者没上线时,消息会存在 Redis 中 不会及时消费,所以需要处理在消费者离线时生产的消息。
private void processReadMessages(StreamOperations<String, Object, Object> streamOps) {
log.info("processReadMessages...");
List<MapRecord<String, Object, Object>> read = streamOps.read(
Consumer.from(GROUP_NAME, CONSUMER_NAME),
StreamReadOptions.empty().block(Duration.ofSeconds(3)), // 阻塞 3 秒
StreamOffset.create(STREAM_NAME, ReadOffset.lastConsumed()) // 从上次消费位置开始
);
for (MapRecord<String, Object, Object> entries : read) {
onProcess(entries);
}
}
参考
- RocketMQ 顺序消息:https://rocketmq.apache.org/zh/docs/featureBehavior/03fifomessage/
- RocketMQ 顺序消息:https://juejin.cn/post/7017973936654647303
- RocketMQ 实战笔记:https://blog.csdn.net/agonie201218/article/details/125372702
- 详解rocketMQ顺序消息:https://zhuanlan.zhihu.com/p/608612130
- RocketMQ的顺序消费问题:https://blog.csdn.net/qq_40662424/article/details/122977388
- Kafka 顺序消息:https://cloud.tencent.com/developer/article/1839597
- 聊聊 Redis Stream :https://www.cnblogs.com/makemylife/p/18135130
- 消息队列 RocketMQ版:https://www.volcengine.com/docs/6410/131277
- Redis进阶 - 持久化:RDB和AOF机制详解:https://pdai.tech/md/db/nosql-redis/db-redis-x-rdb-aof.html
- Redis能保证数据不丢失吗:https://www.cnblogs.com/bossma/p/18029874