在许多编程语言中,如 Go 和 Python,协程是作为高效并发的解决方案,通过用户级调度来实现轻量级的并发。Go 通过 goroutine 提供了类似的高并发能力,Python 则通过 async/await 实现了协程的控制流,Java 的虚拟线程借鉴了这些语言的思路,使用用户级调度来取代操作系统调度,从而降低了线程创建和切换的成本。
并发模型
传统线程模型
使用最传统的线程模型时,调用阻塞接口时,线程会阻塞在调用处,等阻塞返回才能继续执行,或者在多线程场景,操作系统会进行线程切换,去执行其他线程,效果如下图:
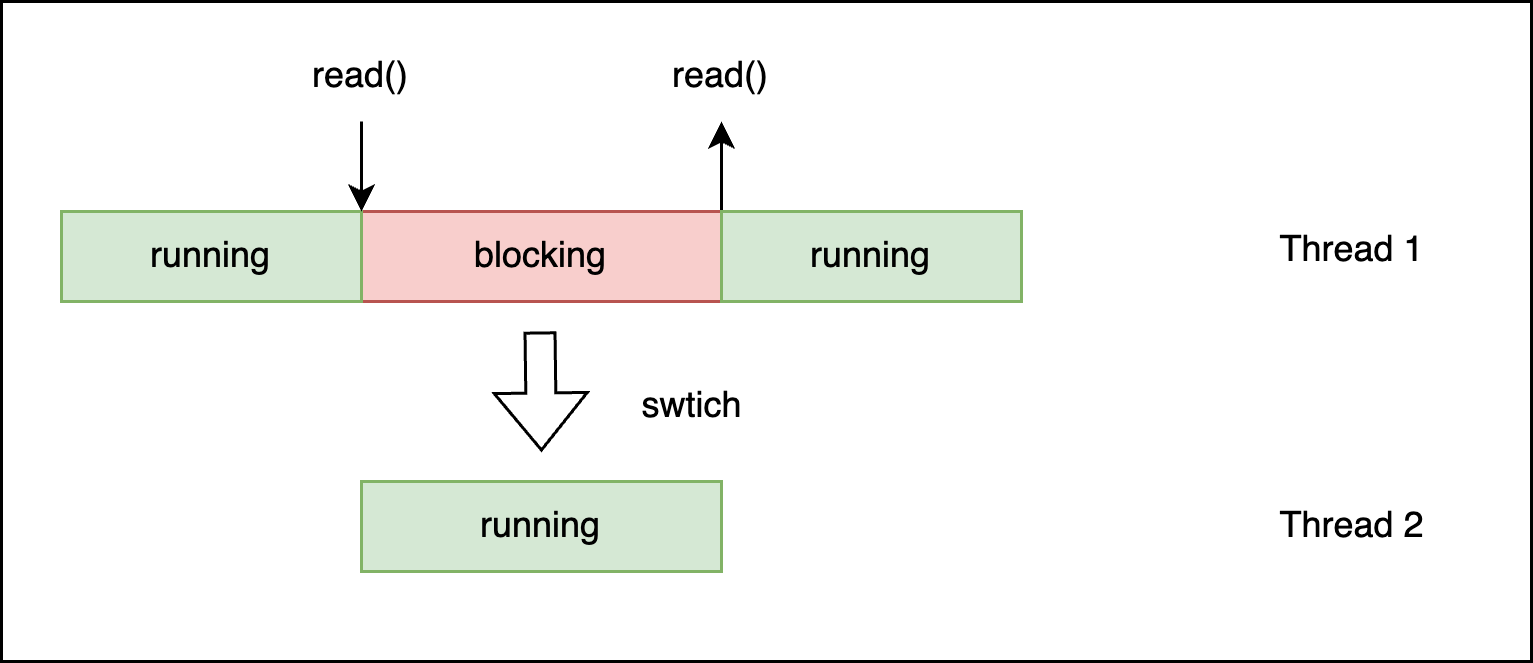
使用多线程可以提高执行效率,但是当另一个线程执行完,并且没用其他线程执行时,仍然会造成阻塞在线程1的位置,影响执行效率,效果如下图:
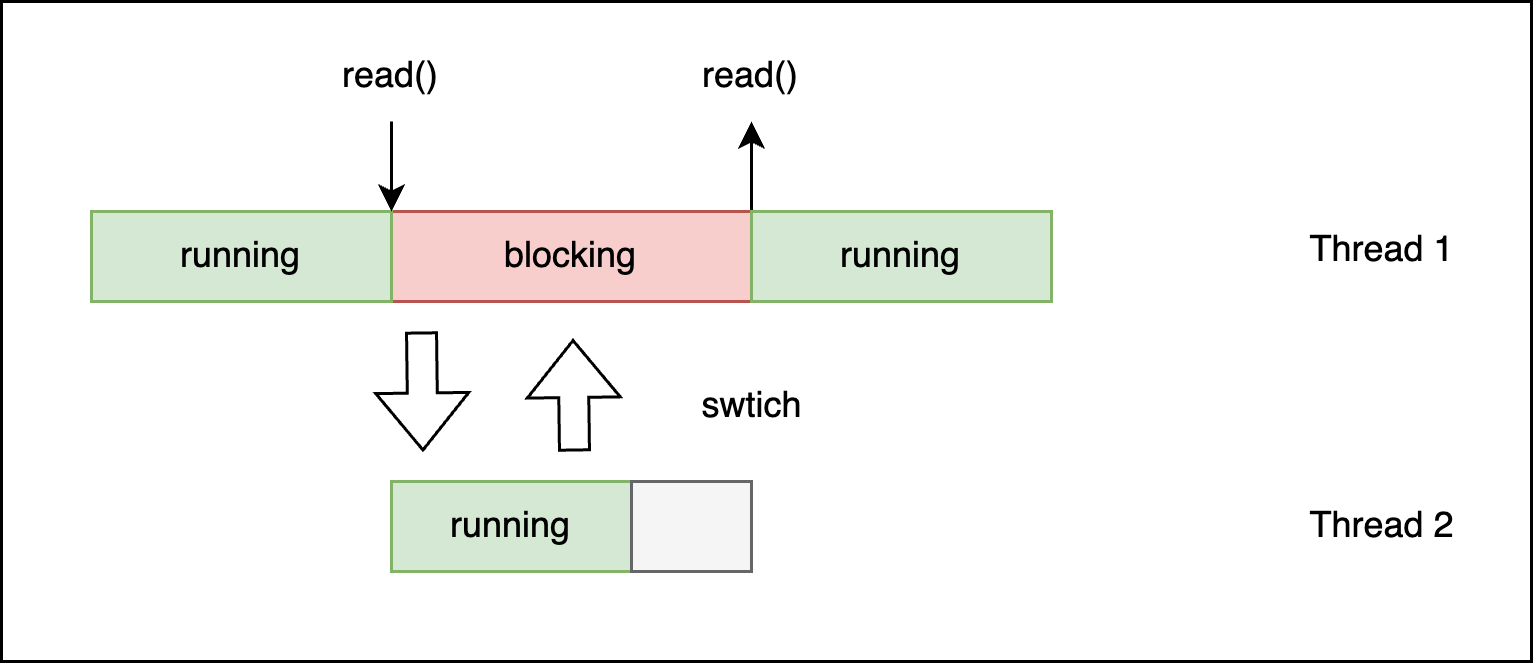
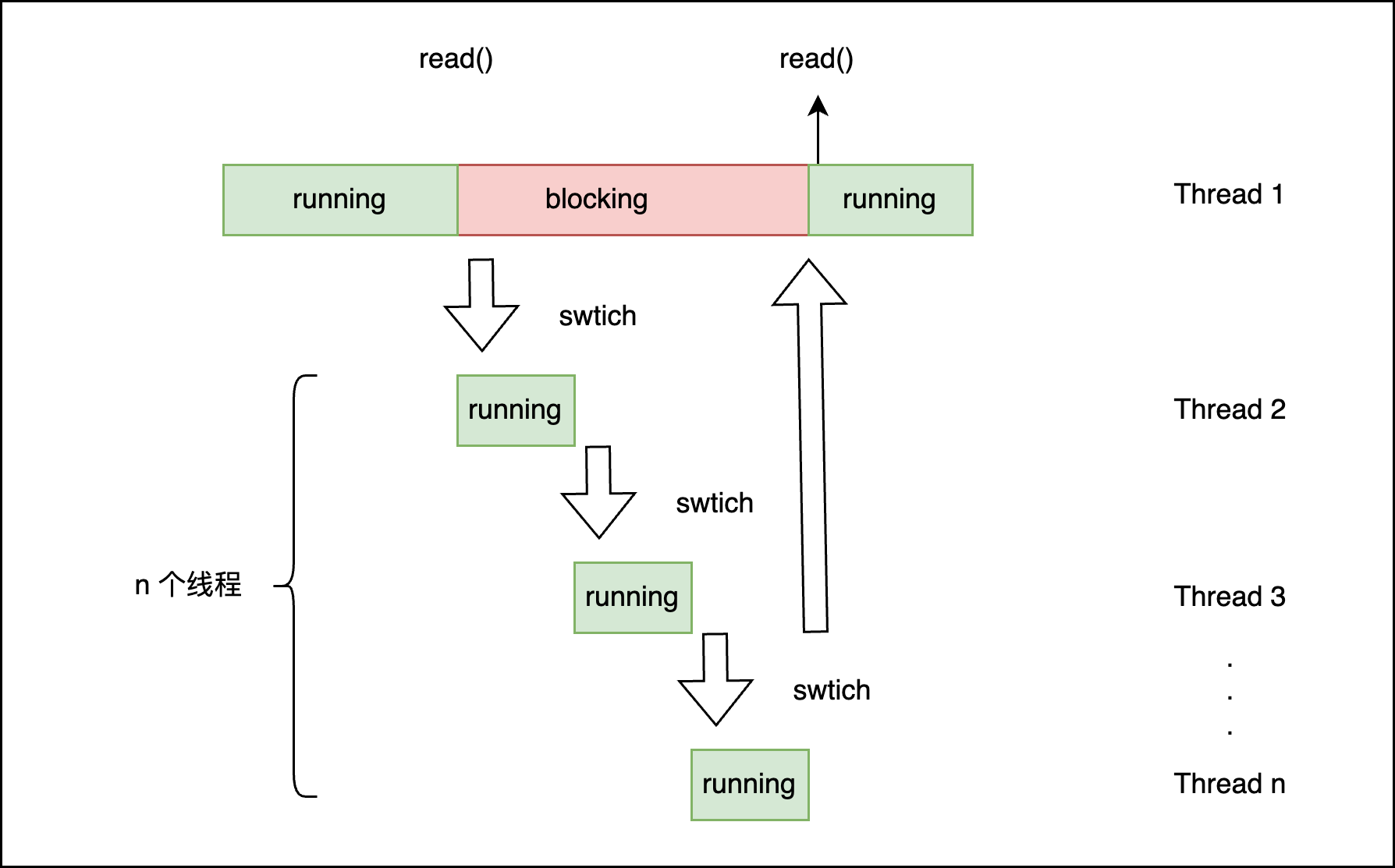
当线程需要执行的任务较多时,有多个线程可以执行任务,多个线程间进行上下文切换,最后等到最开始的线程阻塞返回继续执行,这样可以充分利用 CPU 资源,效果如下图:
上图展示的任务是小任务,当切换到重量级任务时,比如也阻塞在 read() 调用上,效果如下图:
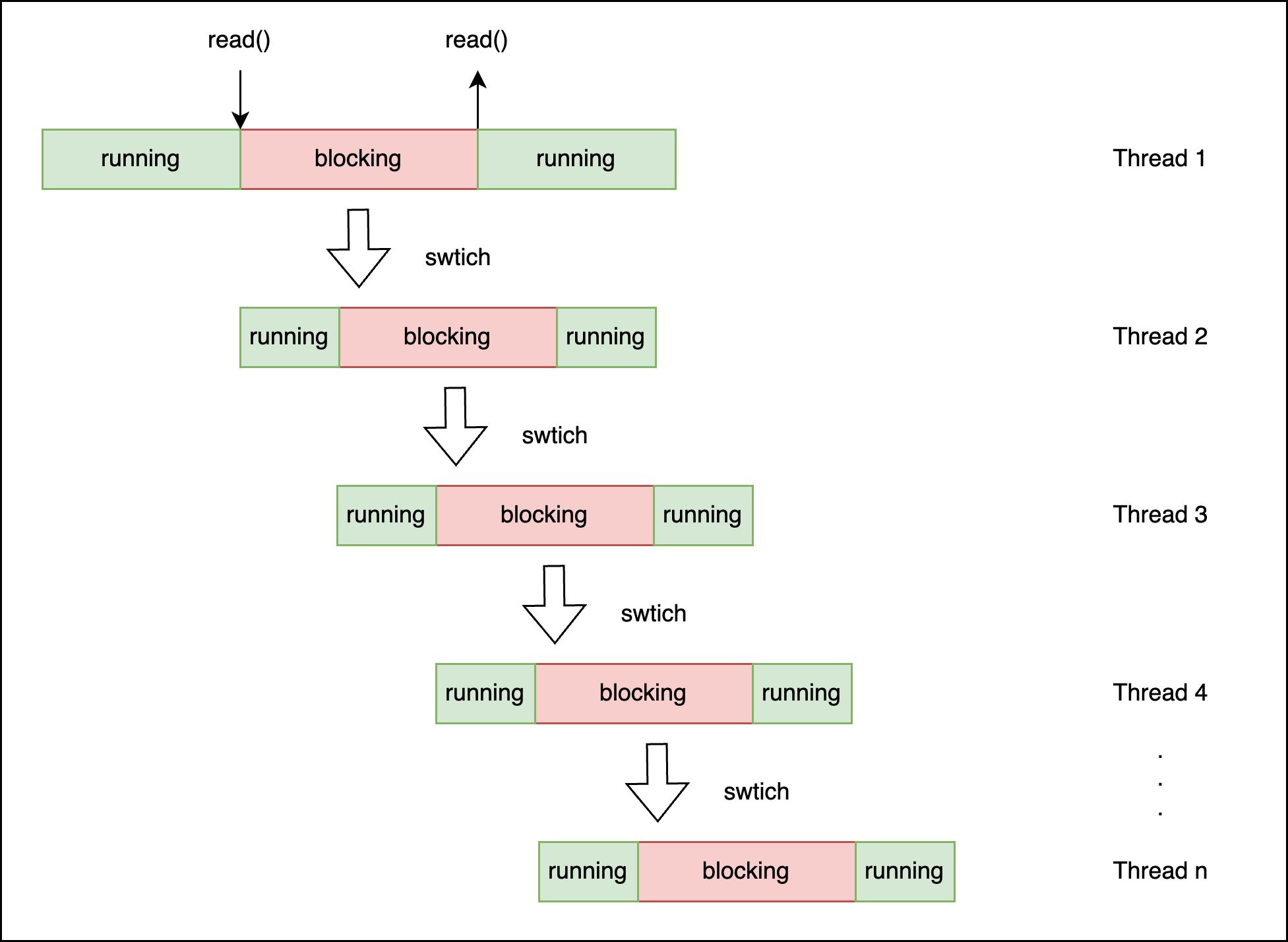
在业务高峰的场景,可能会需要大量的线程时,这种方式不能满足要求,因为线程的数量是有限制的,不能无节制的新建线程。
# cat /proc/sys/kernel/pid_max
4194304
尽管可以通过设置调整这个值,但是在一般的开发语言中,比如说 Java,一个线程需要占用 1MB 大小的内存。如果要处理常见的 C10K 问题,需要处理 10000 的请求,则需要 10000 线程,需要 10GB 的内存,这显然是不合适的。所以需要一种处理机制,通过少量的请求,这就是 Reactor,接下来,我们来看看 Netty 的 Reactor。
Netty Reactor
Netty 的 Reactor 模式通过事件驱动和多线程的结合,利用操作系统的 I/O 多路复用机制,高效地处理大量并发的网络请求。它的核心是 Selector(事件选择器)和 Reactor(事件分发器),使得高并发的网络服务能够在少量线程的支持下运行,从而提供高效的性能。Netty 的 Reactor 结构图如下(图源从内核角度看IO模型):
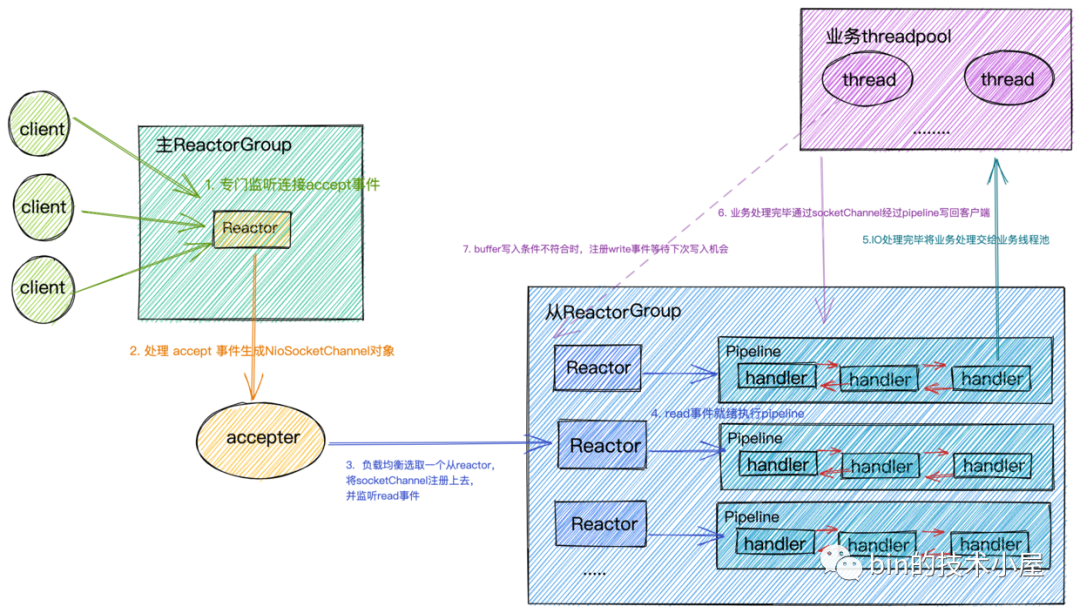
这种模型也有一种弊端,那就是线程数受 SubReactorGroup 限制,以 Dubbo 的一个场景为例,当业务逻辑复杂,调用耗时高,且并发较高时,业务处理逻辑会一直占用 Dubbo 的工作线程,线程资源很容易耗尽,触发线程池拒绝策略,结果如下:
RejectedExecutionException:Thread pool is EXHAUSTED (线程池耗尽了)! Thread Name: DubboServerHandler-xx.xx.xxx:2201, Pool Size: 300 (active: 283, core: 300, max: 300, largest: 300)
可以看到,基于线程设计并发模型主要有三个限制:
- 上下文切换(影响时延):每次上下文切换时,操作系统需要保存和加载线程的上下文,频繁的上下文切换会增加额外的延迟,影响任务的响应时间。
- 阻塞(影响 CPU 利用率):阻塞操作如果频繁发生,会导致 CPU 利用率降低,系统的计算能力没有得到充分利用。例如,等待磁盘 IO 操作时,线程被阻塞,CPU 只能用来处理其他非阻塞任务。
- 数量少(影响并发):线程数量受内存限制,无法支持十万,百万级别的线程数量。
Netty 的 Reactor 通过 epoll 的事件驱动与非阻塞调用,可以充分降低应用在执行过程中“阻塞”的影响,提高了应用的执行效率。但是线程的上下文切换仍会影响部分执行效率。
理想线程模型
如何突破上面的三个限制?理想的是没有上下文切换,充分利用 CPU,可以几乎无限的创建“线程”。如果应用线程与内核线程绑定,就无法实现,所以需要在用户态实现“线程”,称之为“协程”,协程需要实现以下几个内容。
- 不使用内核线程,与内核线程解绑。
- 当执行到阻塞方法时,不进行内核线程的上下文切换,进行用户线程自己的上下文切换。
- 进行上下文切换后,切换到另一个线程需要高效。
- 协程的数量几乎是无限的。
基本效果如下:
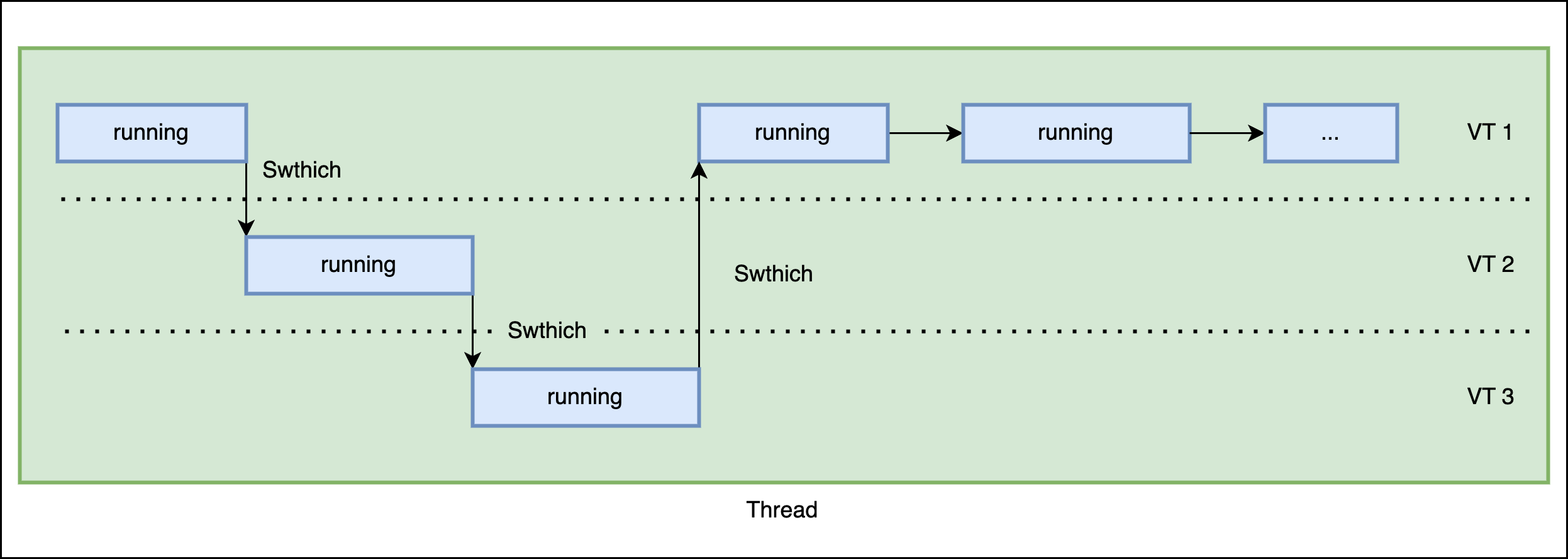
协程的实现有两个关键点:
- 上下文:进行协程的上下文切换时,如何保存与恢复上下文现场?
- 调度:协程如何进行高效调度?
接下来看看主流开发语言是怎么实现协程的。
Golang GMP
Golang 是一门天然支持协程的语言,goroutine 是其对协程的本土化实现。其强依附于 GMP 体系而生的。所以说要了解 Golang 的协程,了解GMP 是必不可少的。GMP 的架构如下(图源 Golang GMP 万字洗髓经):
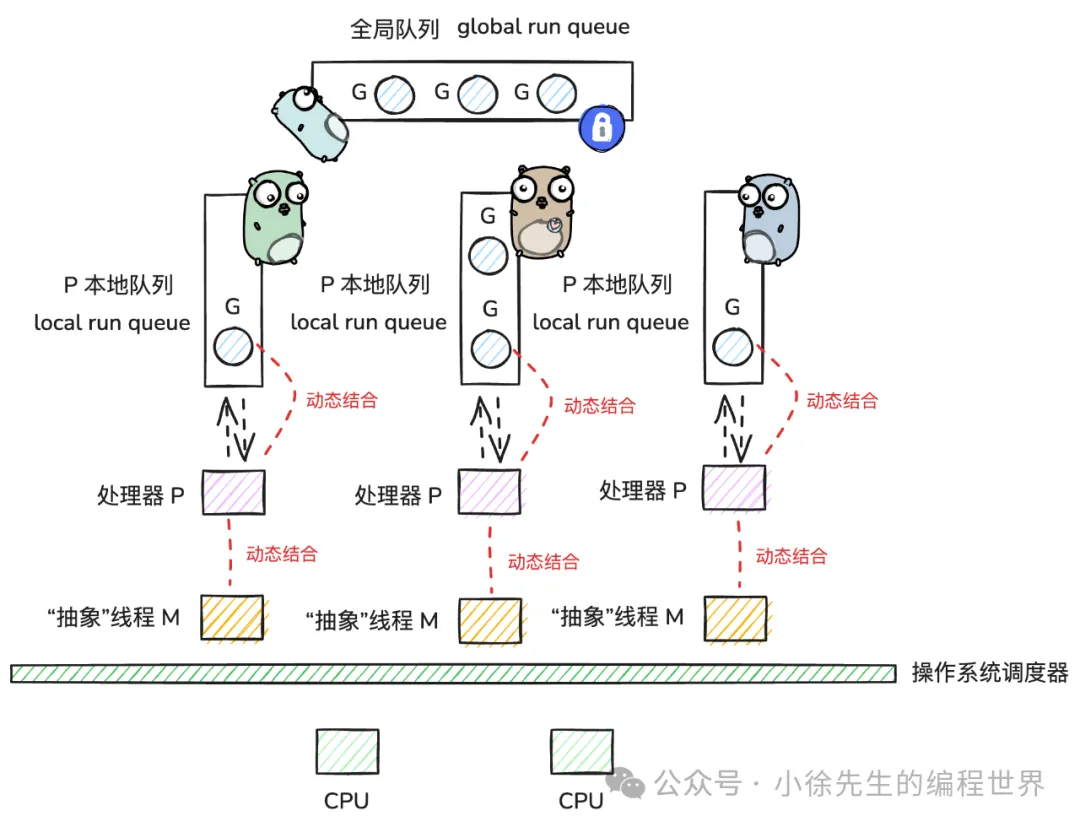
- G 即 goroutine,是 golang 中对协程的抽象;
- M 即 machine,是 golang 中对线程的抽象;
- P 即 processor,是 golang 中的调度器;
GMP 上下文
GMP 的上下文信息放在 g 这个结构中,代码如下:
type g struct {
// ...
m *m // 在 p 的代理,负责执行当前 g 的 m;
// ...
sched gobuf
// ...
}
type gobuf struct {
sp uintptr // 保存 CPU 的 rsp 寄存器的值,指向函数调用栈栈顶;
pc uintptr // 保存 CPU 的 rip 寄存器的值,指向程序下一条执行指令的地址;
ret uintptr // 保存系统调用的返回值;
bp uintptr // 保存 CPU 的 rbp 寄存器的值,存储函数栈帧的起始位置.
}
GMP 数据结构定义为 runtime/runtime2.go 文件中
通过CPU寄存器的值保存到这个数据结构中,可以实现保存与恢复协程的执行位置。
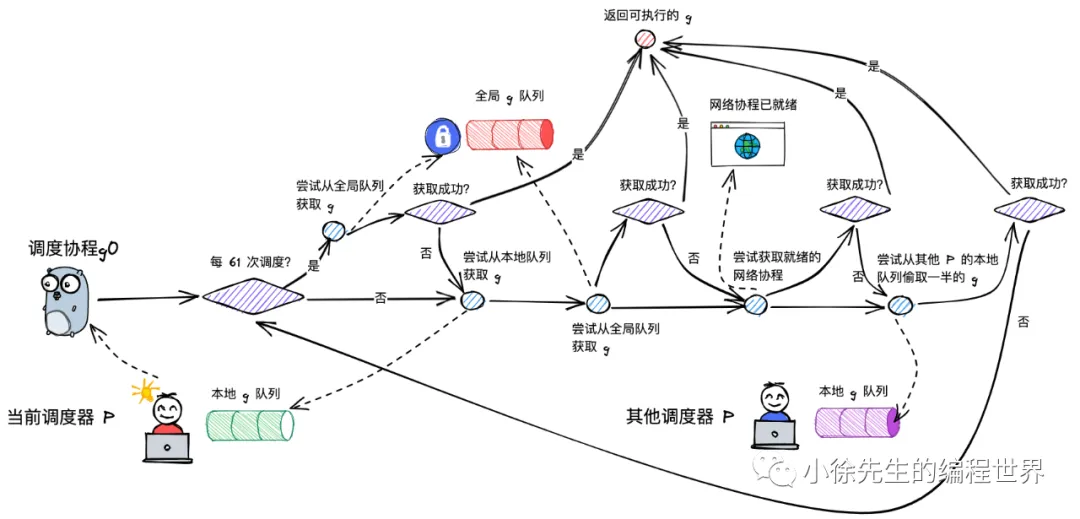
GMP 调度
processor 是 golang 中的调度器,详细调度流程如下:
虚拟线程
Java 程序是怎么执行的
Java 程序的执行离不开 JVM 运行时数据区, 其结构图如下(图源 JVM 内部结构详解):
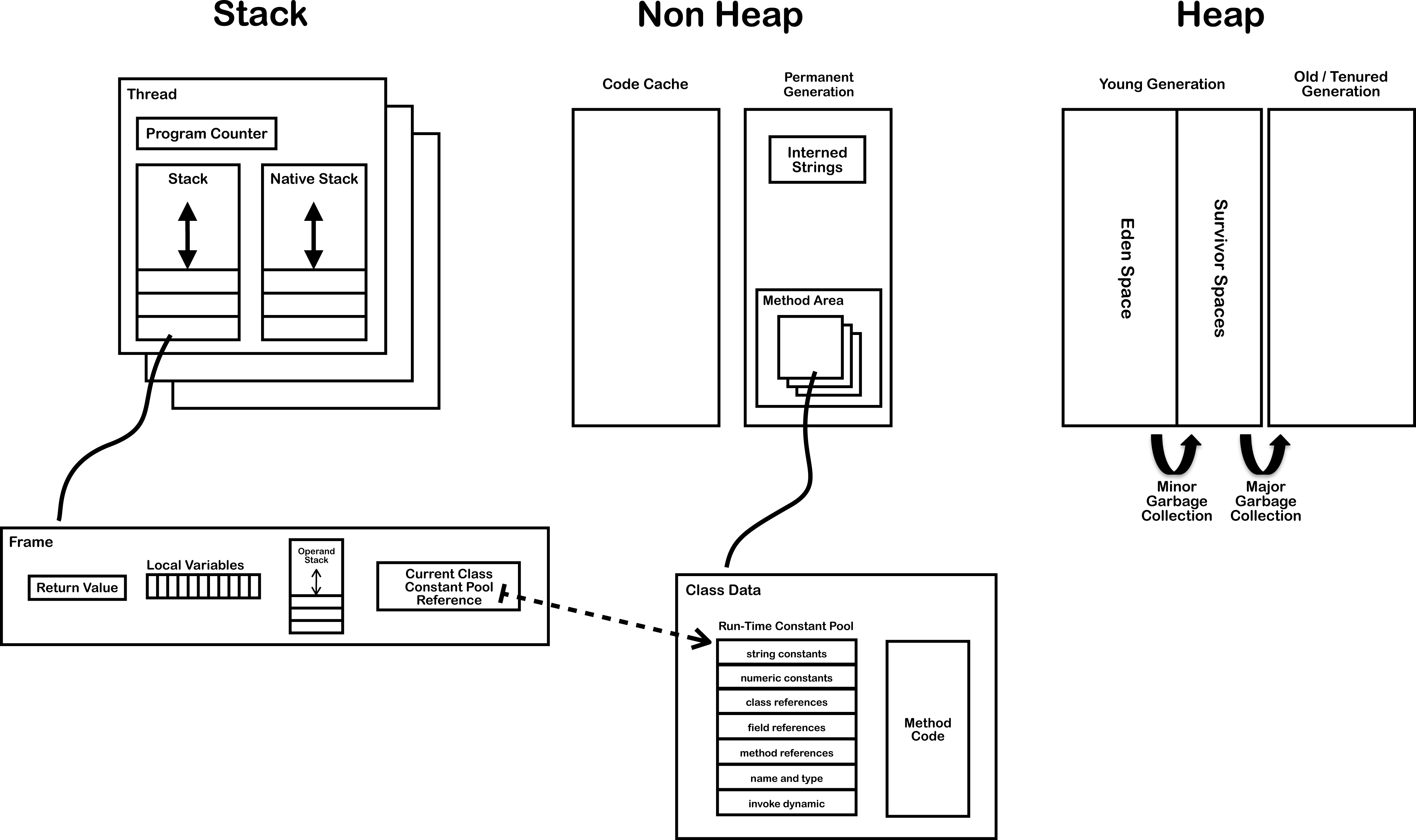
当 JVM 执行一个方法时,整个过程可以概括为:
- 程序计数器:指向当前方法的字节码指令。
- 虚拟机栈:为每个方法调用创建栈帧,栈帧中有局部变量表、操作数栈等。
- 操作数栈:用于临时存储数据并进行计算。
- 字节码指令的执行:JVM 逐条执行字节码,操作数栈与局部变量表相互作用,程序计数器控制程序流。
假设我们有以下代码:
public class Test {
public static void main(String[] args) {
int a = 10;
int b = 20;
int sum = a + b;
System.out.println(sum);
}
}
在 JVM 执行时的过程如下:
-
程序计数器:指向 main 方法的字节码。
-
栈帧:为 main 方法创建栈帧,初始化局部变量表,其中 a 和 b 的值为 10 和 20,操作数栈为空。
-
字节码指令
- iconst_10:将常量 10 压入操作数栈。
- istore_1:将栈顶的 10 存入局部变量表的 a。
- iconst_20:将常量 20 压入操作数栈。
- istore_2:将栈顶的 20 存入局部变量表的 b。
- iload_1:将 a(值为 10)加载到操作数栈。
- iload_2:将 b(值为 20)加载到操作数栈。
- iadd:将栈顶的两个值 10 和 20 相加,结果 30 压入操作数栈。
- istore_3:将 30 存入局部变量表的 sum。
-
方法结束:输出 sum,栈帧销毁,方法返回。
这段代码在 main 线程里执行的,在正常情况, main 线程会将代码全部执行完,如果想要达到 main 线程去执行其他任务,而不是由操作系统另外一个线程去执行其他任务。该怎么做呢?比如说下面的这段代码
public class Test {
public static void main(String[] args) {
int a = 10;
int b = 20;
// 阻塞读取一个文件
read("fileName");
int sum = a + b;
System.out.println(sum);
}
}
在阻塞读物文件的时候,main 线程去执行其他任务,而不是另外一个线程去执行任务,这样就没有操作系统线程的上下文切换的开销,也能充分利用 CPU 资源。那么,该如何实现呢?首先想到的是要将 a 与 b 的值保存起来,需要记录当前方法执行的的位置与变量信息,这些值保存在“程序计数器”与操作数栈,也就是需要保存当前“用户线程”的上下文,切换到其他“用户线程”,实现上下文的中断与恢复,确保在阻塞返回后可以继续执行当前方法的正确性。可以看看 JDK21 “用户线程”的实现—— 虚拟线程(VirtualThread,VT)。
VT 的结构
虚拟线程 可以由下面这个公式概括:
VirtualThread = Continuation + Scheduler + Runnable
-
Continuation 直译为"连续",是用户真实任务的包装器,也是任务切换虚拟线程与平台线程之间数据转移的一个句柄,它提供的 yield 操作可以实现任务上下文的中断和恢复。使语言可以在任意点保存执行状态并且在之后的某个点返回。
-
Scheduler 也就是执行器,由它将任务提交到具体的载体线程池中执行;虚拟线程框架提供了一个默认的 FIFO 的 ForkJoinPool 用于执行虚拟线程任务。
-
Runnable 则是真正的任务包装器,由 Scheduler 负责提交到载体线程池中执行。
VT 上下文
VirtualThread 上下文的实现主要是 jdk.internal.vm.Continuation 这个类实现,主要有三个关键方法 yield() 、run() 方法:
- yield() :的主要作用是挂起当前协程的执行,将控制权返回给调度器,可以用来暂停协程的执行,保存当前执行状态,并以便调度器决定何时恢复该协程的执行。
- run():方法通常会在协程首次执行时调用,负责启动协程的执行,并设置必要的执行上下文。它是协程生命周期的起始点
Java 方法 yield() 的核心实现是 JNI 方法的 gen_continuation_yield() 函数如下:
static void gen_continuation_yield(MacroAssembler* masm,
const VMRegPair* regs,
OopMapSet* oop_maps,
int& frame_complete,
int& framesize_words,
int& compiled_entry_offset) {
Register tmp = R10_ARG8;
const int framesize_bytes = (int)align_up((int)frame::native_abi_reg_args_size, frame::alignment_in_bytes);
framesize_words = framesize_bytes / wordSize;
address start = __ pc();
compiled_entry_offset = __ pc() - start;
// Save return pc and push entry frame
__ mflr(tmp);
__ std(tmp, _abi0(lr), R1_SP); // SP->lr = return_pc
__ push_frame(framesize_bytes , R0); // SP -= frame_size_in_bytes
DEBUG_ONLY(__ block_comment("Frame Complete"));
frame_complete = __ pc() - start;
address last_java_pc = __ pc();
// This nop must be exactly at the PC we push into the frame info.
// We use this nop for fast CodeBlob lookup, associate the OopMap
// with it right away.
__ post_call_nop();
OopMap* map = new OopMap(framesize_bytes / VMRegImpl::stack_slot_size, 1);
oop_maps->add_gc_map(last_java_pc - start, map);
__ calculate_address_from_global_toc(tmp, last_java_pc); // will be relocated
__ set_last_Java_frame(R1_SP, tmp);
__ call_VM_leaf(Continuation::freeze_entry(), R16_thread, R1_SP);
__ reset_last_Java_frame();
Label L_pinned;
__ cmpwi(CCR0, R3_RET, 0);
__ bne(CCR0, L_pinned);
// yield succeeded
// Pop frames of continuation including this stub's frame
__ ld_ptr(R1_SP, JavaThread::cont_entry_offset(), R16_thread);
// The frame pushed by gen_continuation_enter is on top now again
continuation_enter_cleanup(masm);
// Pop frame and return
Label L_return;
__ bind(L_return);
__ pop_frame();
__ ld(R0, _abi0(lr), R1_SP); // Return pc
__ mtlr(R0);
__ blr();
// yield failed - continuation is pinned
__ bind(L_pinned);
// handle pending exception thrown by freeze
__ ld(tmp, in_bytes(JavaThread::pending_exception_offset()), R16_thread);
__ cmpdi(CCR0, tmp, 0);
__ beq(CCR0, L_return); // return if no exception is pending
__ pop_frame();
__ ld(R0, _abi0(lr), R1_SP); // Return pc
__ mtlr(R0);
__ load_const_optimized(tmp, StubRoutines::forward_exception_entry(), R0);
__ mtctr(tmp);
__ bctr();
}
涉及汇编指令的生成、栈帧的管理以及异常处理。代码展示了如何通过 MacroAssembler 来生成虚拟线程挂起(yield)操作的机器代码。笔者对C语言与汇编代码不熟悉,所以由 ChatGPT 解释上述代码:
- 变量初始化与栈帧计算
Register tmp = R10_ARG8; const int framesize_bytes = (int)align_up((int)frame::native_abi_reg_args_size, frame::alignment_in_bytes); framesize_words = framesize_bytes / wordSize; address start = __ pc(); compiled_entry_offset = __ pc() - start;
- Register tmp = R10_ARG8;:定义一个寄存器 tmp 来存储临时值,使用了 R10_ARG8 寄存器。
- framesize_bytes:计算栈帧的大小,并确保它是对齐的。align_up 用于向上对齐栈帧大小。
- framesize_words:将字节大小转换为字(通常为 4 字节或 8 字节),用于栈帧大小的处理。
- start:获取当前指令指针 pc(程序计数器)的位置,之后用于计算生成代码的偏移量。
- 保存返回地址和创建栈帧
__ mflr(tmp); __ std(tmp, _abi0(lr), R1_SP); // SP->lr = return_pc __ push_frame(framesize_bytes , R0); // SP -= frame_size_in_bytes
- mflr(tmp):将当前的链接寄存器(LR)值(即返回地址)加载到 tmp 寄存器中。
- std(tmp, _abi0(lr), R1_SP):将 tmp 寄存器中的值(返回地址)存储到栈上。
- push_frame:生成一个新的栈帧,更新栈指针。
- 生成并记录 OopMap(垃圾回收信息)
__ post_call_nop(); OopMap* map = new OopMap(framesize_bytes / VMRegImpl::stack_slot_size, 1); oop_maps->add_gc_map(last_java_pc - start, map);
- post_call_nop():插入一个 NOP(空操作)指令,用作优化。
- OopMap:生成一个 OopMap 对象,它用于跟踪栈中可能包含的对象引用。OopMap 是垃圾回收时使用的标记数据结构,用于标识栈帧中需要检查的对象引用。
- 调用冻结点(freeze_entry)
__ calculate_address_from_global_toc(tmp, last_java_pc); __ set_last_Java_frame(R1_SP, tmp); __ call_VM_leaf(Continuation::freeze_entry(), R16_thread, R1_SP); __ reset_last_Java_frame();
- 计算从全局表 (TOC) 中获取地址。
- 设置当前虚拟线程的最后一个 Java 栈帧。
- call_VM_leaf:调用 freeze_entry,它可能是一个冻结虚拟线程上下文的入口点,保存当前的执行状态(寄存器、栈等)。
5. 处理 yield 成功和失败的两种情况
Label L_pinned; __ cmpwi(CCR0, R3_RET, 0); __ bne(CCR0, L_pinned); // yield succeeded
- 通过 cmpwi 比较 R3_RET 寄存器的值是否为 0,决定是否进入 yield 成功的分支。如果 R3_RET != 0,则跳转到 L_pinned 标签,表示协程或虚拟线程被“固定”(无法继续执行)。
- yield 成功:恢复栈并返回
__ ld_ptr(R1_SP, JavaThread::cont_entry_offset(), R16_thread); continuation_enter_cleanup(masm); __ pop_frame(); __ ld(R0, _abi0(lr), R1_SP); // Return pc __ mtlr(R0); __ blr();
- 如果 yield 成功,则恢复线程的栈帧信息(ld_ptr),清理栈(continuation_enter_cleanup),然后返回执行。
7. yield 失败:处理异常
__ bind(L_pinned); __ ld(tmp, in_bytes(JavaThread::pending_exception_offset()), R16_thread); __ cmpdi(CCR0, tmp, 0); __ beq(CCR0, L_return); // return if no exception is pending __ pop_frame(); __ ld(R0, _abi0(lr), R1_SP); // Return pc __ mtlr(R0); __ load_const_optimized(tmp, StubRoutines::forward_exception_entry(), R0); __ mtctr(tmp); __ bctr();
- 如果 yield 失败,则检查是否有待处理的异常。如果有异常,将跳转到异常处理例程。
可以看到 yield 主要由4和步骤,核心是保存当前线程的上下文。
- 保存当前线程 freeze_entry 的上下文:包括保存返回地址和创建栈帧。
- 生成与垃圾回收相关的信息:使用 OopMap 来跟踪栈帧中的对象引用。
- 调用虚拟线程的冻结操作:通过 freeze_entry 保持虚拟线程的状态,以便以后恢复。
- 根据 yield 成功与否执行不同操作:成功时恢复栈并返回,失败时处理异常。
VT 调度
调度
对于虚拟线程,JDK 有自己的调度器。JDK 的调度器没有直接将虚拟线程分配给系统线程,而是将虚拟线程分配给平台线程。平台线程由操作系统的线程调度系统调度。JDK 的虚拟线程调度器是一个在 FIFO 模式下运行的类似 ForkJoinPool 的线程池。调度器的并行数量取决于调度器虚拟线程的平台线程数量。默认是 CPU 可用核心数量,可以使用系统属性 jdk.virtualThreadScheduler.parallelism 进行调整。
ForkJoinPool 和 ExecutorService 的工作方式不同,ExecutorService 有一个等待队列来存储它的任务,其中的线程将接收并处理这些任务。而 ForkJoinPool 的每一个线程都有一个等待队列,当一个由线程运行的任务生成另一个任务时,该任务被添加到该线程的等待队列中,当我们运行 Parallel Stream,一个大任务划分成两个小任务时就会发生这种情况。
为了防止线程饥饿问题,当一个线程的等待队列中没有更多的任务时,ForkJoinPool 还实现了另一种模式,称为任务窃取, 也就是说:饥饿线程可以从另一个线程的等待队列中窃取一些任务。这和 Go GMP 模型中 work stealing 机制有异曲同工之妙。
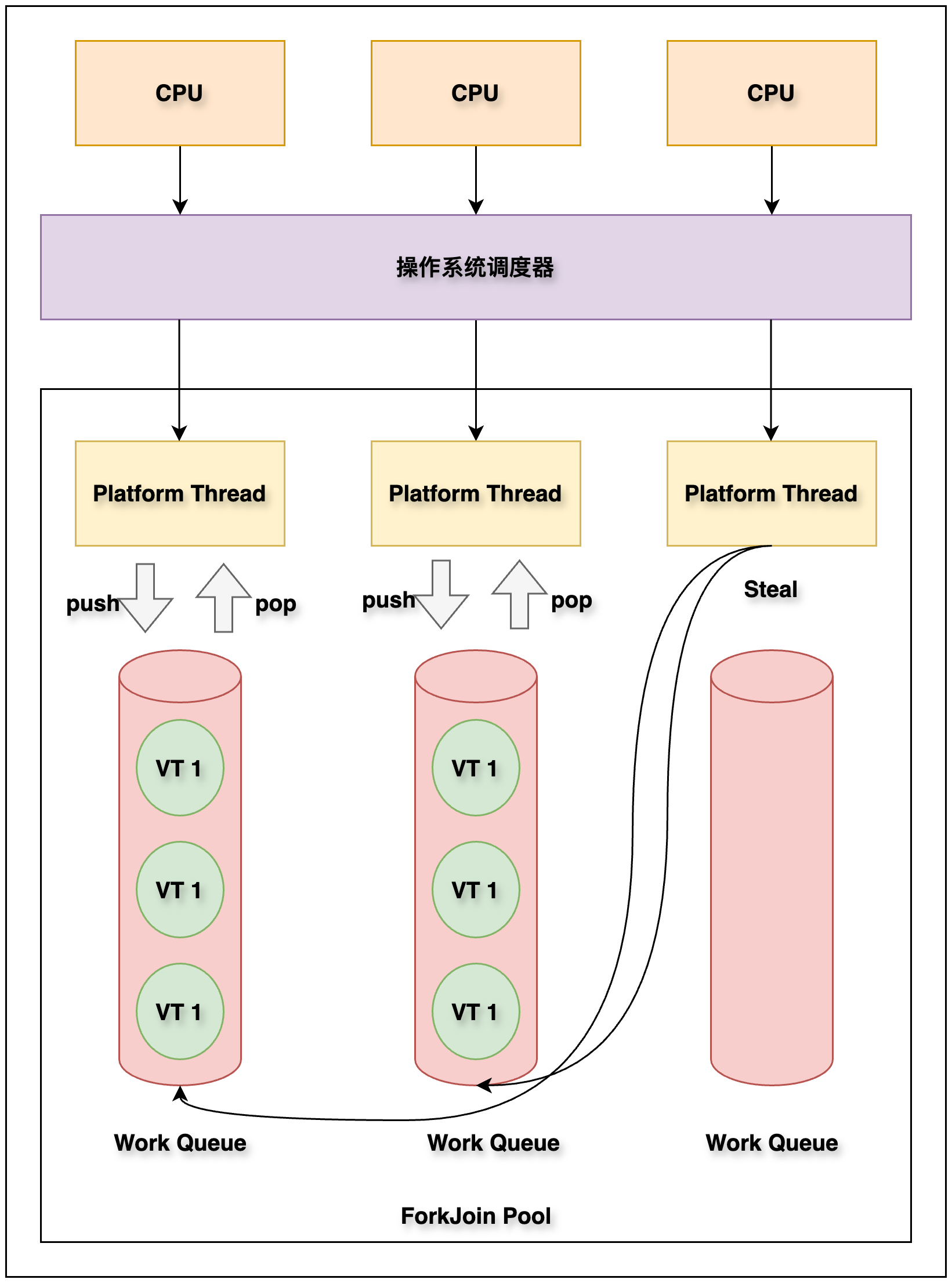
JVM 把虚拟线程分配给平台线程的操作称为 mount(挂载),反过来取消分配平台线程的操作称为 unmount(卸载):
- mount() 操作:虚拟线程挂载到平台线程,虚拟线程中包装的 Continuation 栈数据帧或者引用栈数据会被拷贝到平台线程的线程栈,这是一个从堆复制到栈的过程
- unmount() 操作:虚拟线程从平台线程卸载,大多数虚拟线程中包装的 Continuation 栈数据帧会留在堆内存中
Continuation 的 run 方法就是在开始时调用 mount(),先将虚拟线程挂载到触发平台线程,在 finally 代码块中调用 unmount(),将虚拟线程从平台线程中卸载,简化后的 run 方法代码如下:
/**
* 挂载和运行 Continuation 主体。如果暂停,则从最后一个暂停点继续执行。
*/
public final void run() {
while (true) {
mount();
// dosonmething
try {
boolean isVirtualThread = (scope == JLA.virtualThreadContinuationScope());
if (!isStarted()) {
enterSpecial(this, false, isVirtualThread);
}
} finally {
fence();
try {
JLA.setContinuation(currentCarrierThread(), this.parent);
unmount();
JLA.setScopedValueCache(null);
} catch (Throwable e) {
e.printStackTrace(); System.exit(1);
}
}
}
}
状态
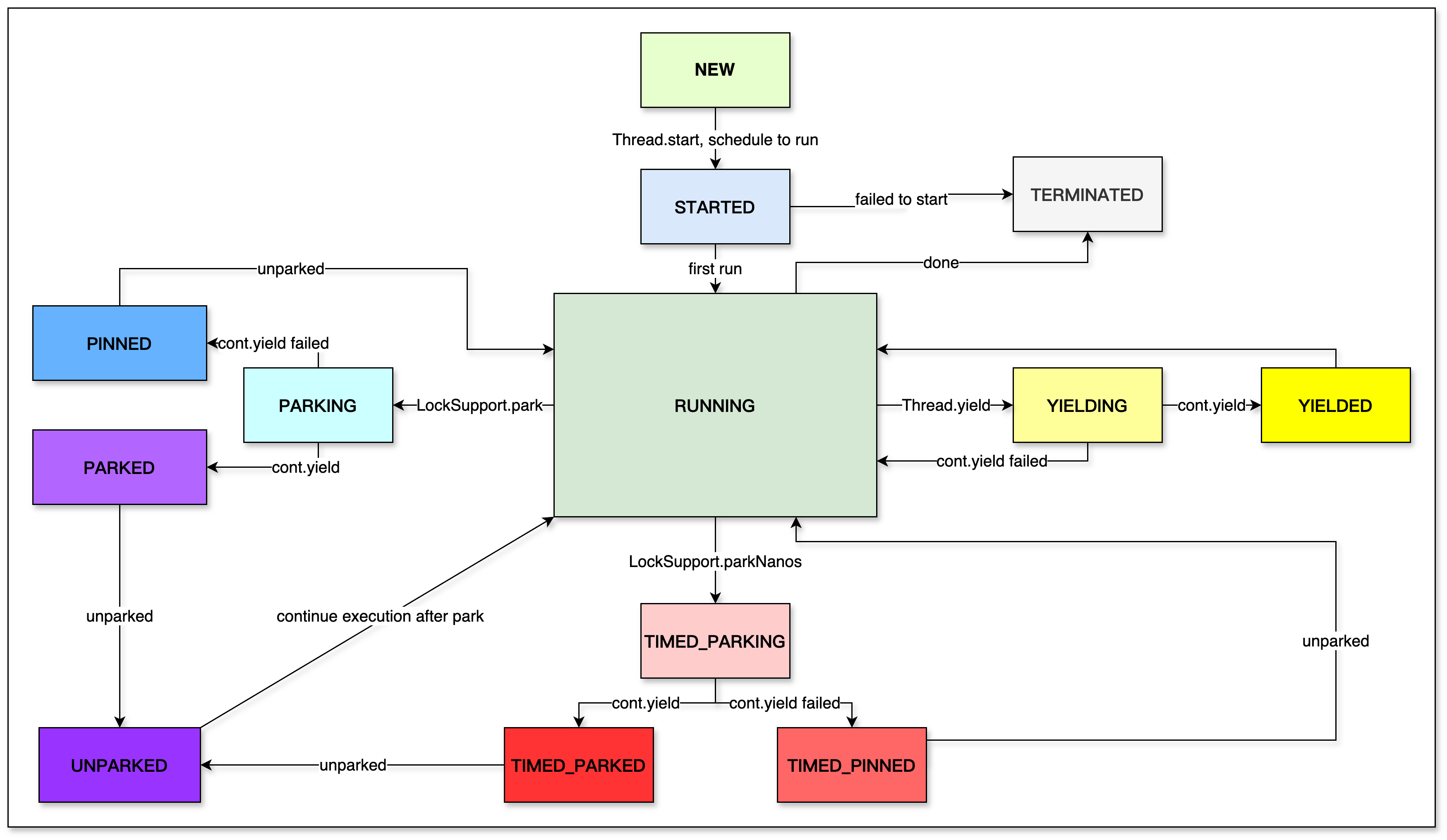
VirtualThread 源码定义的状态有有十多种,具体如下:
- NEW:线程新创建,尚未启动。
- STARTED:线程已开始,但未进入运行状态。
- RUNNING:线程正在执行中。
- PARKING:线程处于挂起状态,正在等待唤醒。
- PARKED:线程挂起且等待被唤醒。
- PINNED:线程挂起,但由于某些原因需要保持在当前载体上,直到被唤醒。
- TIMED_PARKING:线程处于定时挂起状态,等待指定时间后自动唤醒。
- TIMED_PARKED:线程定时挂起并等待唤醒。
- TIMED_PINNED:线程定时挂起,且保持在当前载体上。
- UNPARKED:线程被唤醒,准备继续执行。
- YIELDING:线程正在执行 Thread.yield() 方法,要求调度器让其他线程执行。
- YIELDED:线程执行 yield() 成功,准备继续执行。
- TERMINATED:线程执行完成,终止。
源码上由虚拟线程的状态转换,如下图:
性能对比
说了这么多,现在来实际验证一下虚拟线程的性能,到底有没有宣传的这么高效。测试的主要是使用 Spring、虚拟线程、Netty、Vertx、以及 Golang 的 fasthttp 五种方式编写一个 ping/pong 功能的 HTTP 程序。
Spring
Spring 使用的 tomcat 作为默认的 web 程序,不修改任何配置,代码如下:
@RestController
public class PingPongController {
@GetMapping("/ping")
public String java(String param) {
return "pong";
}
}
application.properties
server.port=8081
VirtualThread
使用 HttpServer + VirtualThread 程序
public class PingPongVirtualThreadServer {
public static void main(String[] args) throws IOException {
// 创建一个虚拟线程池
ExecutorService virtualThreadPool = Executors.newVirtualThreadPerTaskExecutor();
// 创建 HTTP 服务器
HttpServer server = HttpServer.create(new InetSocketAddress("localhost", 8082), 0);
// 注册 "/ping" 的处理器
server.createContext("/ping", new PingHandler());
// 使用虚拟线程池处理 HTTP 请求
server.setExecutor(virtualThreadPool);
// 启动服务器
System.out.println("Server is running on http://localhost:8082");
server.start();
}
// 定义处理器类
static class PingHandler implements HttpHandler {
@Override
public void handle(HttpExchange exchange) throws IOException {
// 返回的响应内容
String response = "pong";
// 设置状态码和响应长度
exchange.sendResponseHeaders(200, response.getBytes().length);
try (OutputStream os = exchange.getResponseBody()) {
// 写入响应内容
os.write(response.getBytes());
}
}
}
}
Netty
使用 Netty 编写的 Ping/Pong HTTP 服务如下:
public class PingPongNettyServer {
public static void main(String[] args) {
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup(200);
try {
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
ChannelPipeline pipeline = ch.pipeline();
// 添加HTTP请求编解码器
pipeline.addLast("codec", new HttpServerCodec());
// 添加自定义的处理器
pipeline.addLast("handler", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof HttpRequest) {
HttpRequest request = (HttpRequest) msg;
// 获取请求的URI和方法
String uri = request.uri();
// 根据不同的URI返回不同的内容
String content;
if (uri.equals("/ping")) {
content = "pong";
} else {
content = "error";
}
// 构建HTTP响应
FullHttpResponse response = new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, HttpResponseStatus.OK);
response.content().writeBytes(content.getBytes());
response.headers().set(HttpHeaderNames.CONTENT_TYPE, "text/plain");
response.headers().set(HttpHeaderNames.CONTENT_LENGTH, response.content().readableBytes());
// 返回HTTP响应
ctx.writeAndFlush(response);
}
}
});
}
});
ChannelFuture future = bootstrap.bind(8083).sync();
future.channel().closeFuture().sync();
} catch (InterruptedException e) {
throw new RuntimeException();
} finally {
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
}
}
}
Vert.x
Vert.x 是 JVM 上构建响应式应用的工具,其使用 事件循环(eventloop) 多路复用并发处理工作负载。当您使用 异步I/O 时,可以用更少的线程处理更多的并发连接。 当一个任务发生了I/O操作时,异步I/O不会阻塞线程,而是执行其他待处理的任务,待到I/O结果准备好后再继续执行该任务。效果图如下(图源 Vert.x 和响应式编程简介):
使用 Vert.x 开发一个 HTTP 程序非常简单,一个简易的 ping/pong 如下:
public class PingPongVertxServer extends AbstractVerticle {
public static void main(String[] args) {
// 创建 Vert.x 实例
Vertx vertx = Vertx.vertx();
// 部署 Verticle
vertx.deployVerticle(new PingPongVertxServer());
}
@Override
public void start() {
// 创建 HTTP 服务器
var server = vertx.createHttpServer();
// 创建路由器
Router router = Router.router(vertx);
// 定义 "/ping" 路由
router.get("/ping").handler(ctx -> {
ctx.response()
.putHeader("Content-Type", "text/plain")
.end("pong"); // 返回 "pong"
});
// 启动服务器并绑定到端口 8089
server.requestHandler(router).listen(8084, http -> {
if (http.succeeded()) {
System.out.println("Server is running at http://localhost:8084/ping");
} else {
System.err.println("Failed to start the server");
}
});
}
}
Vertx 在最新的版本中支持了虚拟线程,详见:What's new in Vert.x 4.5 ,在选项中设置 虚拟线程模式即可在 Vertx 中使用虚拟线程,代码如下:
// Run the verticle a on virtual thread
vertx.deployVerticle(verticle, new DeploymentOptions().setThreadingModel(ThreadingModel.VIRTUAL_THREAD));
理论上,使用虚拟线程可以提高程序的执行效率,效果如何呢?等会会揭晓。
fasthttp(Go)
Golang 是天生支持协程的语言,而 fasthttp 更是一款高性能 web 库,做 web 服务宣称是 net/http 的 10 倍,号称性能最强的 Iris 框架底层用的就是 fasthttp 库。安装 fasthttp 命令如下:
go get -u github.com/valyala/fasthttp
使用 fasthttp 开发一个 ping/pong 服务如下:
package main
import (
"github.com/valyala/fasthttp"
"log"
)
func main() {
PingPongWeb()
}
func PingPongFasthttp() {
// 定义请求处理函数
requestHandler := func(ctx *fasthttp.RequestCtx) {
switch string(ctx.Path()) {
case "/ping":
// 设置响应内容
ctx.SetContentType("text/plain; charset=utf-8")
ctx.SetStatusCode(fasthttp.StatusOK)
ctx.SetBodyString("pong")
default:
// 处理未知路径
ctx.Error("unsupported path", fasthttp.StatusNotFound)
}
}
// 启动服务器
port := ":8089"
log.Printf("Server is running at http://localhost%s/ping", port)
if err := fasthttp.ListenAndServe(port, requestHandler); err != nil {
log.Fatalf("Error in ListenAndServe: %s", err)
}
}
压测汇总
压测平台
软件:Jmeter
硬件:MacBook Air M2, 16G
前置负载:CPU usage :5%;Memory usage:76%
压测结果如图:
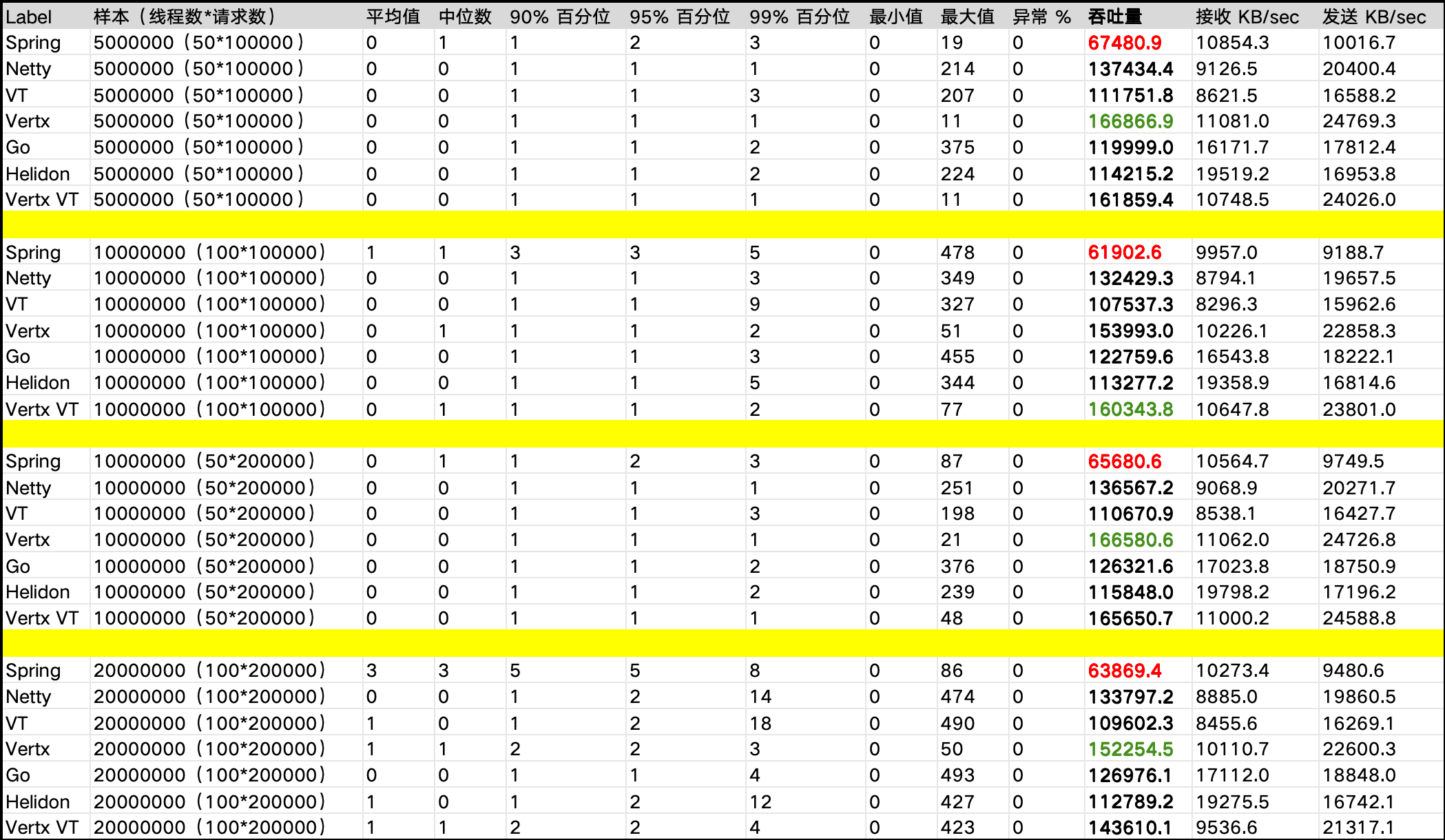
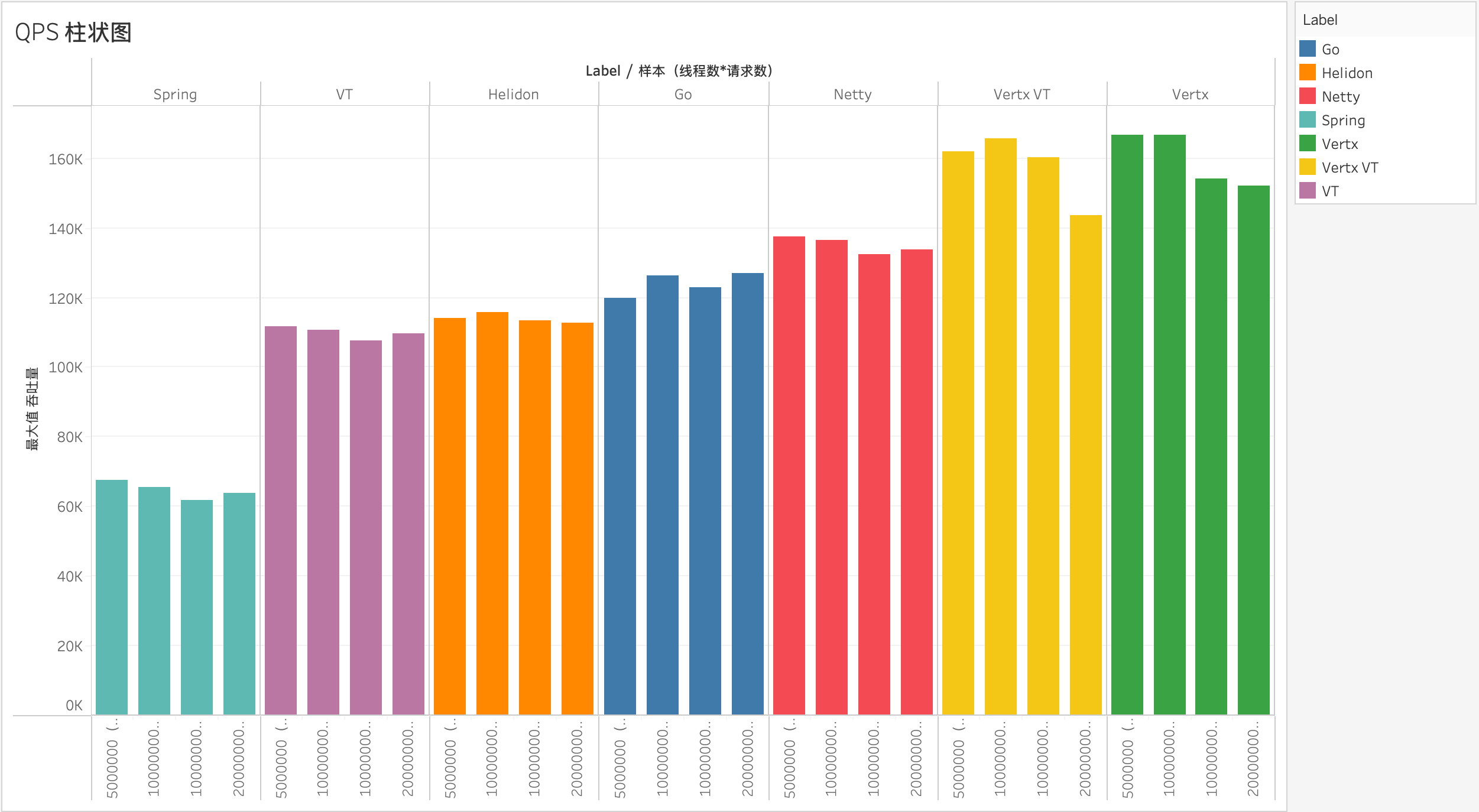
如上表格展示了不同框架在相同请求量下的性能表现,包括吞吐量、延迟等关键指标,Vertx 框架的吞吐量远超其他框架,达到166866.9 请求/秒,表现出色,而 Spring 框架的吞吐量相对较低,这可能与其架构设计有关。虽然 Go的吞吐量较高,但其最大延迟显著高于其他框架,可能存在潜在的性能瓶颈。各程序在各种种并发负载的表现如下:
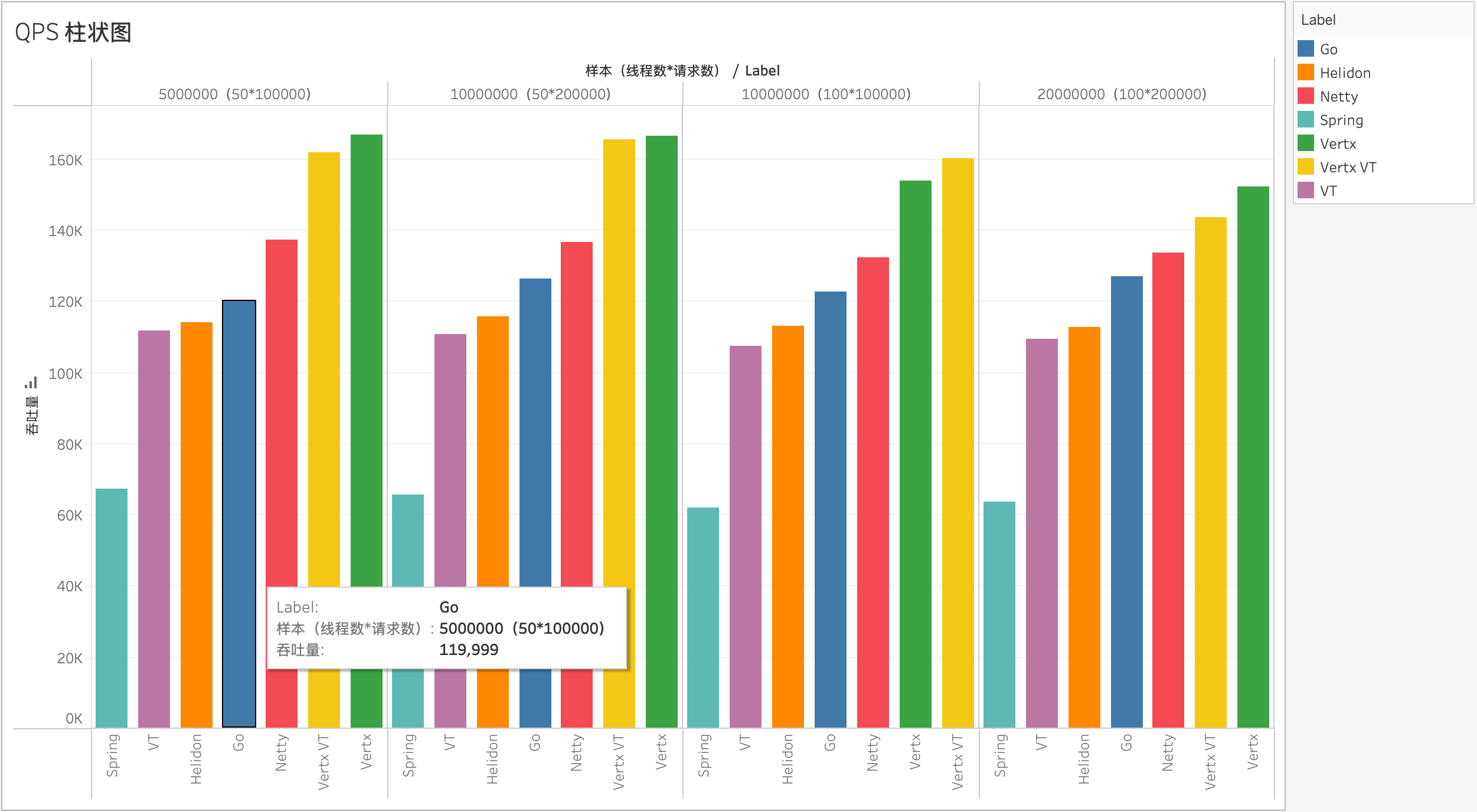
根据并发度分组,各程序的性能对比如下:
接下来根据结果分析性能表现的原因。
Spring 为什么如此糟糕?
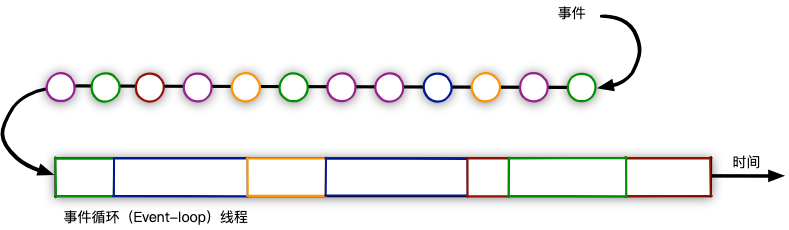
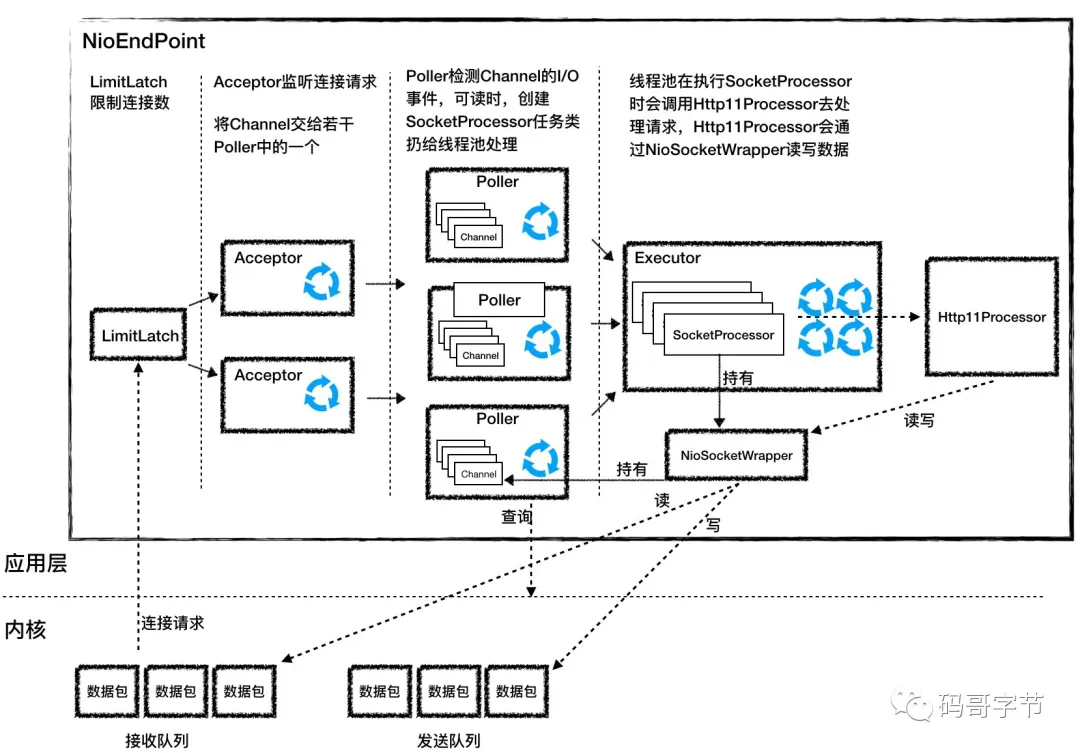
Spring MVC 是基于 Servlet的Web 框架,在本质上都是阻塞和多线程的,每个连接都会使⽤⼀个线程。在请求处理的时候,会在线程池中拉取⼀个⼯作者(worker)线程来对请求进⾏处理。同时,请求线程是阻塞的,直到⼯作者线程提⽰它已经完成为⽌。它将花费更⻓的时间才能将⼯作者线程送回池中,准备处理另⼀个请求。异步的Web框架能够以更少的线程获得更⾼的可扩展性,通常它们只需要与CPU核⼼数量相同的线程。通过使⽤所谓的事件轮询(event looping)机制(如下图所⽰),这些框架能够⽤⼀个线程处理很多请求,这样每次连接的成本会更低。SpringBoot 默认使用的是 Tomcat,Tomcat的底层实现是 Java 的 NIO,其网络线程模型如下图(图源Tomcat 架构原理解析到架构设计借鉴)。
尽管 NIO 相较于传统的 BIO 线程模型有了很大的提升,但是还是不及 Netty 这种 对 NIO 优化到了极致的网络框架,所以在 Spring 基于 Netty 也孵化了 Spring WebFlux 项目。
VT 不如 goroutine
VT 之所以在性能上不如 Golang 的 goroutine,可能有以下两个原因:
- Go 语言本身的优势:goroutine 在上下文切换时只需要保存少量的 CPU 寄存器,而虚拟线程则需要保存整个栈帧空间和程序计数器,这使得虚拟线程在冻结和恢复过程中需要更多的开销,导致性能不如 goroutine。
- fasthttp 的优势:fasthttp 是 Golang 生态中最知名的高性能 HTTP 框架,它针对 HTTP 场景进行了大量优化。而目前虚拟线程缺乏类似的高性能库支持,限制了其在高并发场景中的优势。
Go 真有这么快?
从上述性能表现来看,Golang 在性能上与 Netty 持平,但与 Vert.x 的差距较大,可能有以下几个原因:
- 压测性能瓶颈:压测平台可能无法支持更高的吞吐量,导致测试结果无法充分展现 Golang 的潜力。
- processor 数量限制:Golang 的默认处理器数量为 CPU 核心数(如 8 核),而 Netty 配置了 200 个工作线程,这为其提供了更强的并发处理能力。
此外,从上述分析可以看出,goroutine 的高效并非是 Golang 的核心优势。Golang 自 2011 年开源,但直到 2018 年才随着云原生技术的崛起而逐渐流行,成为云原生领域的主流语言。Golang 受欢迎的原因主要是其编译与运行速度较快,支持交叉编译,并且可以直接运行在操作系统上。实际上,Java 也能够实现与 Golang 协程相当,甚至更优的性能表现。
Vert.x 为什么快?
为什么同样是异步与事件驱动的组合,Netty 的性能表现会落后于 Vert.x 这么多?以 Netty 编写的程序太简陋?无法达到最优的性能表现?
Vert.x 在某些场景下性能优于 Netty,主要原因包括:
1. 更高效的线程模型和内置优化。
3. 针对常见场景(如 HTTP)的深度优化。
4. 更友好的异步编程模型和生态支持。
Vert.x 的性能优势并非绝对。如果需要极致的性能优化或自定义协议,Netty 仍然是一个优秀的选择。
Vert.x 的 VT 提升不大?
将 Vert.x 与它的虚拟线程模式拉出来对比,如下图:
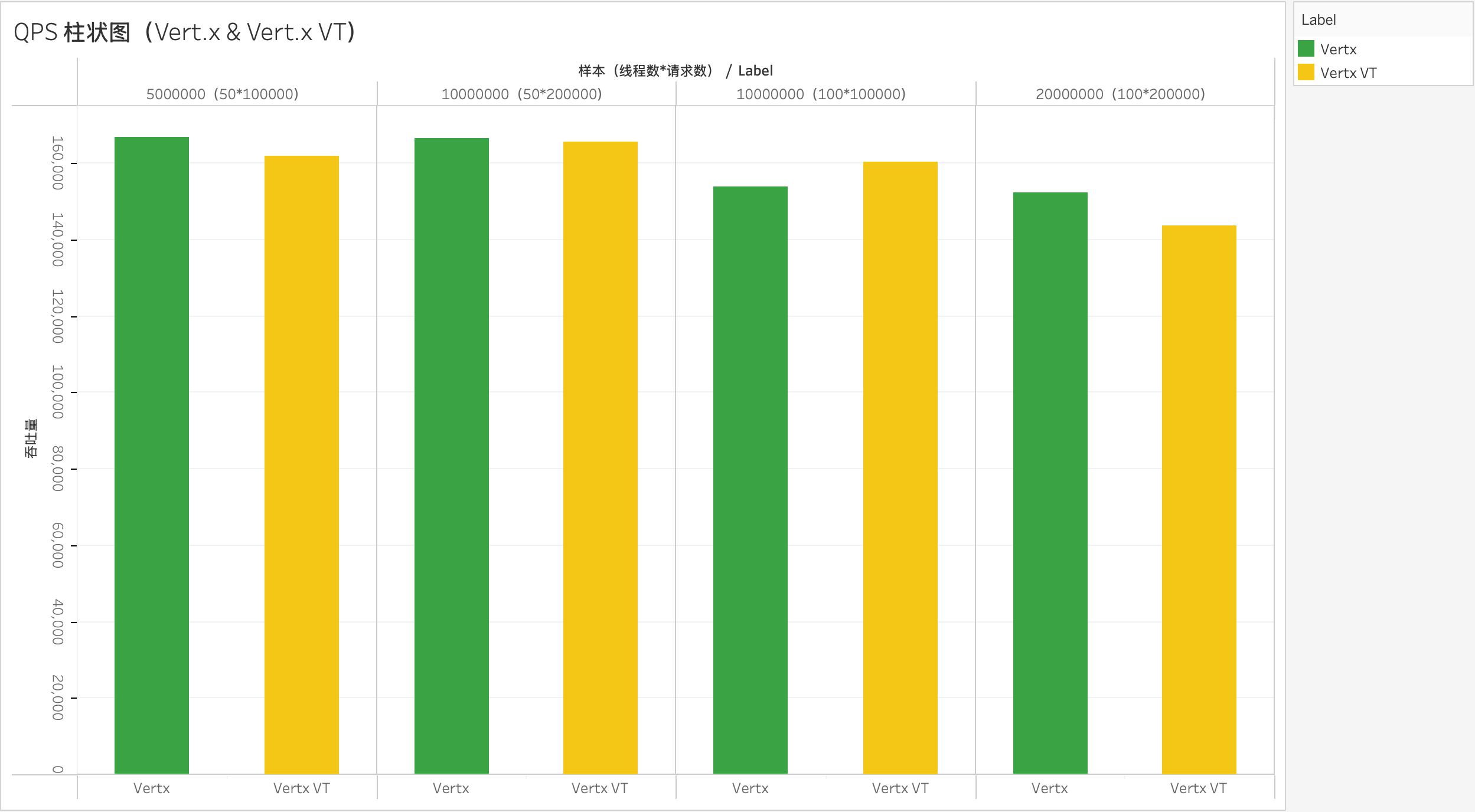
从测试结果来看,虚拟线程模型并未带来显著的性能提升,仅在 100*100000 (线程数 * 请求数)场景下稍微领先于传统实现。在大多数情况下,其性能仍不及原生的 Vert.x 框架。结合 Spring 与纯虚拟线程的对比分析,可以得出以下结论:
- 在性能较低的框架(Spring-Web)中,虚拟线程能够显著提升并发处理能力。
- 在高效框架(Netty 和 Vert.x)中,虚拟线程的性能提升微弱,尚不足以成为开发者迁移的驱动力。因此,期望虚拟线程在后续版本中能带来更大的优化与改进。
扩展问题
VT VS epoll
虚拟线程可以极大的提高程序的并发性能,Epoll 是内核强大事件通知机制,可以以此开发高效的网络应用服务器,但是在与 虚拟线程结合时,可能会遇到三个问题:
- epoll wait 是会阻塞在调用处的,这里阻塞的是线程还是协程?
- epoll wait 是被内核唤醒的,唤醒对象是线程,如果是协程,那么该唤醒那个协程呢?
- epoll 是为了解决线程多,不能复用这个问题的,多线程消耗大,但是协程没有这个问题,也要 epoll?
STW 与 yield
与虚拟线程在方法(栈帧)会保留与恢复上下文类似,JVM GC 中的STW(Stop-The-World ) 也会暂停与恢复栈帧,它们有什么相似之处吗?接下来详细剖析一下。
STW 会暂停所有线程(除了 GC 自身的线程),暂停的线程会保持其当前的执行状态,包括栈帧、程序计数器 (PC)、以及操作数栈等信息。STW 会暂停线程在任意的安全点 (SafePoint)。安全点是 JVM 中的特殊位置,通常位于方法调用点、回边跳转点(如循环)、异常处理点。确保在进行垃圾回收、栈压缩等操作时,可以暂停所有线程,从而保证线程的堆栈一致性和安全性。如果线程不在安全点上,JVM 会让其继续运行到下一个安全点后再暂停。如果线程处于 native 方法调用或其他非 Java 代码执行状态,GC 会等待线程返回到 Java 代码中。
保留方式
- GC Root 分析:GC 会扫描所有线程的栈帧,找到栈帧中引用的对象,作为 GC Roots。
- 栈帧快照:JVM 暂停线程后,会记录当前线程的栈帧信息(包括 PC 和操作数栈)。这些信息是 GC 分析引用关系的重要基础。
冻结信息
- 当前指令(由 PC 指定)。
- 作数栈上的中间计算结果。
- 局部变量表中的数据。
线程恢复
暂停不会丢失或破坏线程的执行状态,GC 完成后,线程会从暂停点继续执行,使用保留的 PC 和栈帧信息。
特殊场景
-
编译器优化:JIT 编译器可能会优化代码,移除一些变量或将变量存储到寄存器中。为了支持 GC,JIT 编译器会在安全点生成相关的 OopMap,帮助 GC 恢复被优化掉的对象引用。
-
异步安全点:如果线程未在安全点,GC 会等待线程到达安全点(通过轮询或其他机制)。
VT 的不足
参考:https://www.bilibili.com/read/cv32443900
-
pin 线程引发的问题比预期严重,需要修改的库繁多。
-
非抢占设计与切换消耗不适合 CPU 密集计算型任务。
-
ThreadLocal 很常用,很难去掉,ScopedLocal 不能解决所有问题。
虚拟线程池的必要性
在许多 Java 虚拟线程的教程中,都说了因为虚拟线程的轻量级特性,池化虚拟线程不值得推荐,但是在 Golang 生态中,有个非常著名的协程池框架——Ants,作为协程届的先驱,Golang 都有自己的协程池,是先见之明,还是做无用功?
参考文章
- 聊透 Netty 核心引擎 Reactor 的运转架构:https://mp.weixin.qq.com/s/g69upk3juqsq6LbwmtitcQ
- Golang GMP 万字洗髓经:https://mp.weixin.qq.com/s/BR6SO7bQF4UXQoRdEjorAg
- 万字解析 golang netpoll 底层原理:https://mp.weixin.qq.com/s/_FTvpvLIWfYzgNhOJgKypA
- 虚拟线程原理及性能分析:https://mp.weixin.qq.com/s/vdLXhZdWyxc6K-D3Aj03LA
- Java 虚拟线程探究与性能解析:https://mp.weixin.qq.com/s/0h33MMzUau8Al4H9p8V9Vg
- VirtualThread 源码透视:https://www.cnblogs.com/throwable/p/16758997.html
- 虚拟线程如何大幅提高系统吞吐量:https://mp.weixin.qq.com/s/yyApBXxpXxVwttr01Hld6Q
- 虚拟线程目前不推荐上生产的个人思考:https://www.bilibili.com/read/cv32443900
- Project Loom:https://cr.openjdk.java.net/~rpressler/loom/loom/JVMLS2018.pdf
- ants:https://github.com/panjf2000/ants
- Go 每日一库之 ants:https://darjun.github.io/2021/06/03/godailylib/ants/
- Golang 协程池 Ants 实现原理:https://mp.weixin.qq.com/s/Uctu_uKHk5oY0EtSZGUvsA
- Tomcat 架构原理解析到架构设计借鉴:https://mp.weixin.qq.com/s/Nsu0_SEA1VyiSD3g07Muow