从 2019 年 Linux 在 5.1 版本发布 io_uring 开始,许多框架都使用了这一项技术,比如 netpoll、rocksdb、ceph、spdk,但是这项技术并没有在 Java 生态中大规模使用,幸运的是,在 Netty 社区,目前正在孵化使用 io_uring 的项目 —— netty-incubator-transport-io_uring,里面提供了新的读写模型 IOUringEventLoop,基于这项技术实现了 io_uring。
为什么都选择选择 epoll?
目前主流的 RPC 或者网络通信框架都底层 Epoll 作为 I/O 通信模块模块,这是为什么呢?
阻塞与非阻塞
先来说说网络的基石 —— Socket,在传统的 Socket 编程中,当发送请求给服务端时,客户端是需要阻塞在 read 函数的,等待网络返回的,例如:
// 等待接收服务器的响应
int bytes_received = read(client_fd, response, BUFFER_SIZE - 1);
if (bytes_received < 0) {
perror("Read from server failed");
} else {
response[bytes_received] = '\0'; // 确保字符串结尾
printf("Received: %s", response);
}
这就是阻塞网络通信。当然,也可以不等待响应返回,而是接受一个异常信息后,再以一个轮询的方式去获取响应返回,在这个轮询内,程序可以让出线程时间,可以去执行其他内容,这就以一个轮询读取响应的方式,提升了程序执行效率,这就是非阻塞。例如:
while (1) {
// 非阻塞读取数据
bytes_received = read(sock, buffer, BUFFER_SIZE - 1);
if (bytes_received > 0) {
// 如果收到数据,处理响应
buffer[bytes_received] = '\0';
printf("Received: %s\n", buffer);
} else if (bytes_received == -1 && errno != EAGAIN && errno != EWOULDBLOCK) {
// 处理读取错误
perror("Read error");
break;
}
// 在轮询中执行其他逻辑
printf("Performing other tasks...\n");
sleep(1); // 模拟其他操作的耗时
// 检查退出条件,模拟程序的停止
if (/* some condition to exit */) {
printf("Exiting...\n");
break;
}
}
但是程序不断去轮询内核网络栈的话,会产生大量的系统调用,这是一笔不小的开销,那么有没有办法优化呢?答案是肯定的,Linux 内核通过内核轮询网络上的可读事件,帮我们减少了大量的系统调用,这是一个巨大的性能提升,比较有代表性的技术有 select 和 poll ,select 的原理是通过文件描述符集合来检查这些描述符的状态(可读、可写、异常)。在调用时,应用层将三个描述符集合(可读、可写、异常)传入内核。内核在一定的超时时间内检查这些描述符的状态,发现变化时返回给应用层,这样可以批量处理多个文件描述符而不必每次逐个检查,大大减少系统调用次数,有一个使用 select 例子是这样的:
while (1) {
// 初始化文件描述符集合
FD_ZERO(&readfds);
FD_SET(sockfd, &readfds);
// 调用 select 并阻塞等待
int activity = select(maxfd + 1, &readfds, NULL, NULL, NULL);
if (FD_ISSET(sockfd, &readfds)) {
// 有新连接到来
newsockfd = accept(sockfd, (struct sockaddr *) &cli_addr, &clilen);
if (newsockfd < 0) {
perror("ERROR on accept");
exit(1);
}
FD_SET(newsockfd, &readfds);
if (newsockfd > maxfd) maxfd = newsockfd;
printf("New connection established.\n");
}
for (int i = sockfd + 1; i <= maxfd; i++) {
if (FD_ISSET(i, &readfds)) {
bzero(buffer, 256);
int n = read(i, buffer, 255);
if (n <= 0) {
close(i);
FD_CLR(i, &readfds);
printf("Connection closed.\n");
} else {
printf("Received message: %s\n", buffer);
}
}
}
}
这样帮助我们节约了大量的系统调用开销,但是 select 与 poll 还有一个巨大问题,有很多技术博客中有提到,那就是监听的网络连接数有限,增删网络连接操作效率低下,这一方面有大量的文章介绍,这里就不展开说了,总结有以下几个缺点。
-
效率较低,select 在处理大量文件描述符时性能下降明显,它采用线性扫描的方式来遍历文件描述符集合。
-
select 调用需要传入 fd 数组,每次调用select需要拷贝一份到内核,每次调用select前都要重新将fd加入文件描述符集合中,因为事件发生后,文件描述符集合将被内核修改,高并发场景下这样的消耗的资源是惊人的。
-
select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。
-
select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。
-
对于大量的文件描述符,需要维护大型的数据结构,会带来额外的开销。
-
文件描述符集合的大小有限制,通常为 FD_SETSIZE,1024,在一些系统中可能会受到限制。
那么 epoll 作为后起之秀,是怎么解决这些问题的呢?主要有如下几点:
- 没有文件描述符限制:epoll 使用红黑树管理文件描述符,几乎没有数量限制,适合大规模连接处理。
- 事件驱动:epoll 采用事件通知机制,每次只有发生事件的文件描述符会返回,避免了遍历整个文件描述符集合,大幅降低了 CPU 消耗。
- 状态保存: epoll 内部保存文件描述符的状态信息,因此只需要注册一次就能持续使用,而不需要重复传递文件描述符集合。
- 减少系统调用:epoll 提供 epoll_ctl、epoll_wait 等系统调用来操作事件,减少了内核与用户空间之间的上下文切换次数,提高了性能。
一个使用 epoll 的例子是:
while (1) {
// 等待事件
int nfds = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
for (n = 0; n < nfds; n++) {
// 处理客户端数据
int client_fd = events[n].data.fd;
char buffer[BUFFER_SIZE];
ssize_t bytes_read = read(client_fd, buffer, sizeof(buffer) - 1);
// 读取并输出接收到的数据
buffer[bytes_read] = '\0';
printf("Received message: %s\n", buffer);
// 简单回显给客户端
if (write(client_fd, buffer, bytes_read) == -1) {
perror("write failed");
close(client_fd);
}
}
代码是不是很简单?来看看epoll 的运行流程,如下图(图源小林coding公众号)。
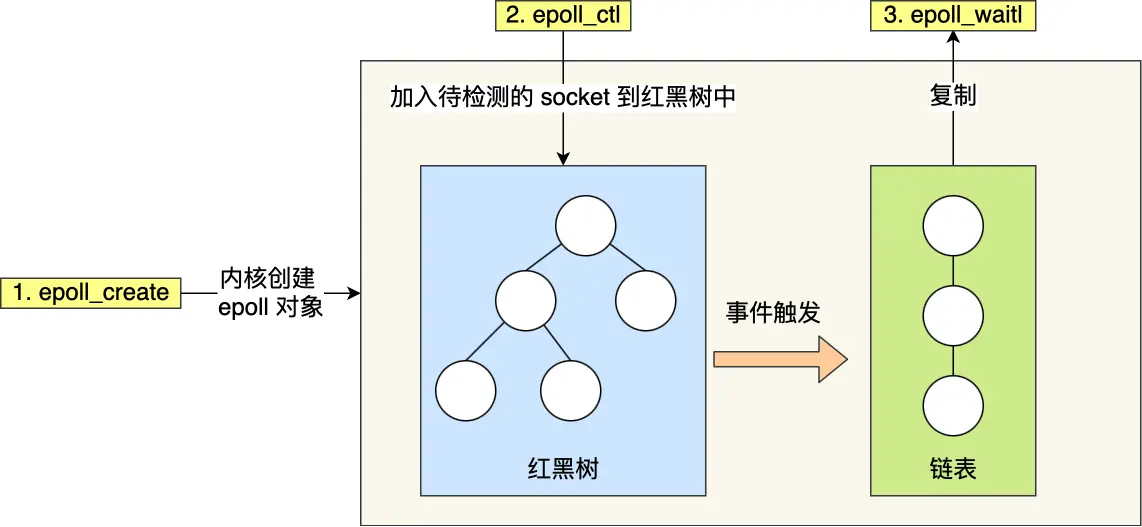
可以清晰的看到 epoll 的 2 大特点:红黑树和就绪链表,epoll 通过 epoll_create 创建,返回的 epoll 文件描述符用于管理和操作其他文件描述符的事件,在使用 epoll 时,我们可以通过 epoll_ctl 将多个文件描述符(例如多个 socket)注册到一个 epoll 实例的红黑树中,以便同时监控多个连接的状态。使用 epoll_wait 可以监视这些文件描述符的状态变化,并获取发生就绪事件的文件描述符列表,而不需要遍历所有的文件描述符,显著提高了性能。
在 Linux 中,文件描述符用于表示文件、网络连接等资源的标识符,socket 和 epoll 都可以视作文件描述符。Socket是网络连接的抽象,通过 socket 系统调用创建,返回一个文件描述符表示该连接。
I/O 发展到了epoll 这一代,基本上是性能与高效的代表,以至于目前主流的 RPC 或者网络框架底层都使用 epoll 作为 I/O 通信模块模块。得益于I/O 多路复用技术,能够处理大量的并发连接,得益于事件驱动模型,使得应用程序可以高效地处理并发请求,尤其在大量长连接场景下,什么是事件驱动模型?下一节我们接着讨论。
事件驱动模型
事件驱动模型?是不是很熟悉?在业务开发在,我们也常常听说过事件驱动模型,用来实现事件响应和任务分发,以实现更灵活的交互和逻辑控制,这与 epoll 的事件驱动模型有什么区别呢?我们接下来看一看。
1. epoll 的事件驱动模型
epoll 采用事件通知机制来监控多个 FD,当文件描述符上发生注册的事件(如可读、可写或错误)时,epoll 会通知应用层处理这些事件。
为什么 select 和 poll 不是事件驱动?之所以不被视为真正的事件驱动模型,是因为它们采用的 I/O 多路复用机制依赖于轮询检查,而不是基于事件通知。每次调用 select 或 poll,系统都会遍历整个文件描述符集合,检查每一个文件描述符的状态。这种方法不是真正的“事件触发”,而是通过反复扫描来找到状态已改变的文件描述符。对于大量文件描述符的场景,这种线性扫描的效率很低。
调用 epoll_wait 等待事件发生,epoll 会返回触发了事件的文件描述符列表。在事件驱动下,应用层只会在发生事件时才去读取或写入数据,避免了不必要的资源消耗,尤其适合处理大量网络连接时的 I/O 操作。
2. 事件驱动模型在业务开发中的应用
在业务开发中,事件驱动模型常用于处理用户界面交互、任务队列、消息通知等。例如:
- 前端开发:通过事件监听用户操作(如点击、输入),然后触发特定的操作逻辑。
- 消息系统:通过事件订阅和发布模式,异步处理消息并进行解耦。
- 任务调度:任务在特定事件(如定时或状态改变)触发时执行。
这些场景下,事件驱动模型可以提高应用的响应速度,便于开发人员将不同的操作逻辑解耦为独立事件处理器。
3. epoll 事件驱动模型与业务事件驱动模型的对比与特点
(1)触发方式:epoll 事件模型是基于内核的事件通知机制。它直接监听 I/O 文件描述符的状态变化,通过 epoll_wait 等待事件触发;业务事件驱动模型通常通过观察者模式实现,监听的是特定事件(如用户操作、消息等),并调用注册的回调函数。
(2)高效性:epoll 使用内核级的事件通知,减少了轮询开销。它采用边缘触发或水平触发模式,避免了不断重复地处理相同事件;业务开发中事件驱动模型的效率则依赖于语言和框架的设计,例如事件循环和异步回调机制。
(3)适用场景:epoll 专注于高并发 I/O 场景,尤其是需要同时处理大量网络连接的服务器,如 HTTP 服务器或消息推送服务;业务事件驱动模型更适合用户交互密集、状态管理复杂的场景,如前端用户界面或任务分发系统。
(4)状态管理:epoll 的事件状态由内核管理,应用程序只需注册事件,内核会在事件触发时进行通知;业务开发中的事件驱动模型则需要显式地管理事件状态和回调,处理更多的应用逻辑。
通过 Netty 探析网络包收发的过程
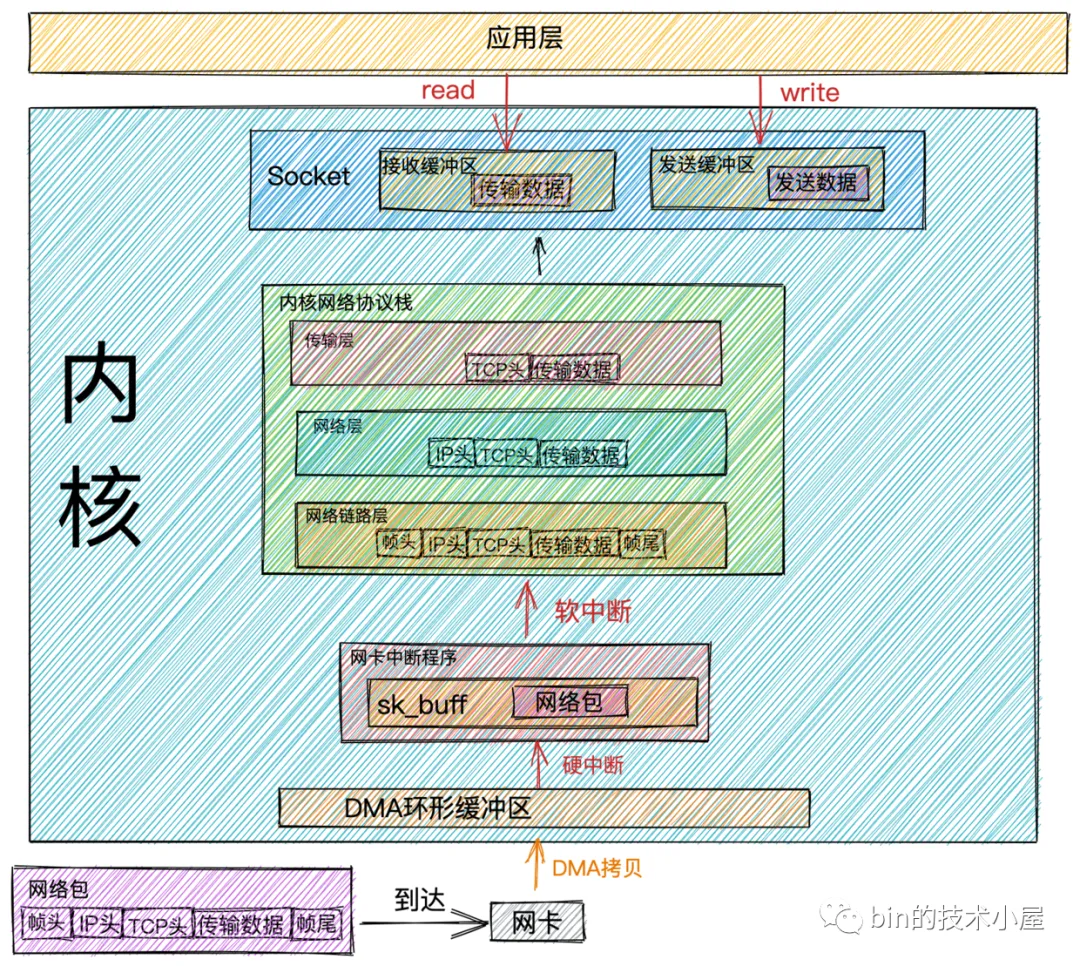
网络包接收核心流程图(图源bin的技术小屋微信公众号):
-
【DMA 拷贝】当网络数据通过网络传输到达网卡时,网卡会将网络数据帧通过 DMA 的方式放到环形缓冲区 RingBuffer 中。
-
【网卡硬中断CPU】当 DMA 操作完成时,网卡会向 CPU 发起一个硬中断,告诉 CPU 有网络数据到达。
-
【CPU 处理硬中断】CPU 调用网卡驱动注册的硬中断响应程序。网卡硬中断响应程序会为网络数据帧创建内核数据结构 sk_buffer,并将网络数据帧拷贝到 sk_buffer 中。
-
【CPU 软中断内核】然后发起软中断请求,通知内核有新的网络数据帧到达。
-
【内核调用IP协议】内核线程 ksoftirqd 发现有软中断请求到来,随后调用网卡驱动注册的 poll 函数,poll 函数将 sk_buffer 中的网络数据包送到内核协议栈中注册的 ip_rcv 函数中。
-
【IP处理】在 ip_rcv 函数中也就是上图中的网络层,取出数据包的 IP 头,判断该数据包下一跳的走向,如果数据包是发送给本机的,则取出传输层的协议类型(TCP或者UDP),并去掉数据包的 IP 头,将数据包交给上图中得传输层处理。
-
【TCP处理】当我们采用的是 TCP 协议时,数据包到达传输层时,会在内核协议栈中的 tcp_rcv 函数处理,在 tcp_rcv 函数中去掉TCP头,根据四元组(源 IP,源端口,目的 IP,目的端口)查找对应的 Socket,如果找到对应的 Socket 则将网络数据包中的传输数据拷贝到 Socket 中的接收缓冲区中。如果没有找到,则发送一个目标不可达的 icmp 包。
-
【应用处理】内核在接收网络数据包时所做的工作我们就介绍完了,现在我们把视角放到应用层,当我们程序通过系统调用 read 读取 Socket 接收缓冲区中的数据时,如果接收缓冲区中没有数据,那么应用程序就会在系统调用上阻塞,直到 Socket 接收缓冲区有数据,然后 CPU将内核空间(Socket 接收缓冲区)的数据拷贝到用户空间,最后系统调用 read 返回,应用程序读取数据。
这是个经典的 Socket 接收网络数据的处理流程,大概是对应如下的伪代码:创建套接字连接后,打印后回显客户端的请求内容。
int main() {
// 创建套接字
server_fd = socket(AF_INET, SOCK_STREAM, 0);
// 省略设置地址和端口、绑定套接字到端口...
// 监听连接
if (listen(server_fd, 3) < 0) {
perror("Listen failed");
close(server_fd);
}
while (1) {
// 循环读取客户端数据
int bytes_read;
while ((bytes_read = read(new_socket, buffer, BUFFER_SIZE - 1)) > 0) {
buffer[bytes_read] = '\0'; // 确保字符串结尾
printf("Received from client: %s\n", buffer);
// 回显收到的数据
send(new_socket, buffer, bytes_read, 0);
printf("Echoed back to client: %s\n", buffer);
}
close(new_socket);
}
// 关闭服务端套接字
close(server_fd);
return 0;
}
上面代码中的 read 函数就是对应图中的应用层 read 内核,这是原始的网络编程方式,而在真实的在开发中,我们常常基于 Netty 进行网络开发,那么 Netty 是怎么接受数据的呢? 其实到 TCP 协议栈之前是类似的,区别在于对于网络数据的 read 与 write,以及与 epoll 的结合。在 Netty 中使用 epoll ,需要先要做三件事,初始化 epoll,将socket 放入 epoll,监听 epoll 的事件,大体上与上文介绍 epoll 类似,详情你可以参考 Netty 事件模型探析。接下来看看 Netty 是怎么接受网络数据包的。
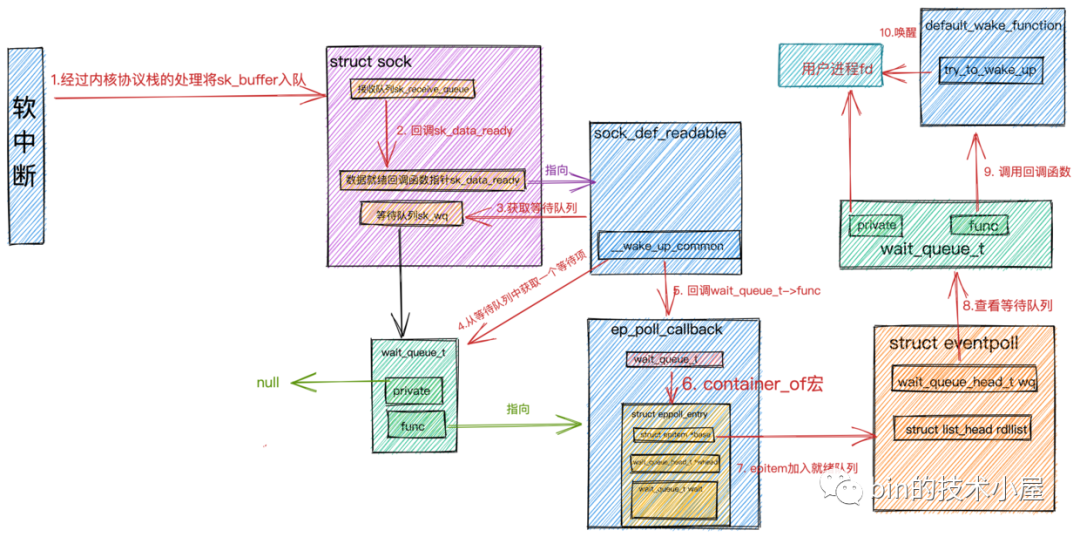
首先是网卡从网卡经过DMA拷贝和协议栈的复制,最后进入 Socket 的接受缓冲区,这里与前文一致,区别在于后续对 epoll 的回调处理,epoll_wait 处理流程图(图源bin的技术小屋微信公众号):
-
【回调 epoll 】当网络数据包在软中断中经过内核协议栈的处理到达 socket 的接收缓冲区时,紧接着会调用socket的数据就绪回调指针 sk_data_ready,回调函数为 sock_def_readable 。在 socket 的等待队列中找出等待项,其中等待项中注册的回调函数为 ep_poll_callback 。
-
【进入就绪队列】在回调函数 ep_poll_callback 中,根据 struct eppoll_entry 中的 struct wait_queue_t wait 通过 container_of宏 找到 eppoll_entry 对象并通过它的 base 指针找到封装 socket 的数据结构 struct epitem ,并将它加入到 epoll 中的就绪队列 rdllist 中。
-
【唤醒等待队列】随后查看 epoll 中的等待队列中是否有等待项,也就是说查看是否有进程阻塞在 epoll_wait 上等待 I/O就绪 的 socket 。如果没有等待项,则软中断处理完成。
-
【返回 socket 的 fd】如果有等待项,则回到注册在等待项中的回调函数 default_wake_function ,在回调函数中唤醒 阻塞进程 ,并将就绪队列 rdllist 中的 epitem 的 I/O就绪 socket信息封装到 struct epoll_event 中返回。
-
【EventLoop读取 socket 数据】EventLoop 拿到 epoll_event 获取 I/O 就绪 的 socket,发起系统I/O调用读取数据。
-
【ChannelHandler 读取】EventLoop 将数据放入 channel,调用上下文的 fireChannelRead 方法,向后传递数据。
ep_poll_callback 是一个内部的回调函数,用于在内核中监控和处理文件描述符的事件。它是内核中实现高效事件通知机制的关键部分。
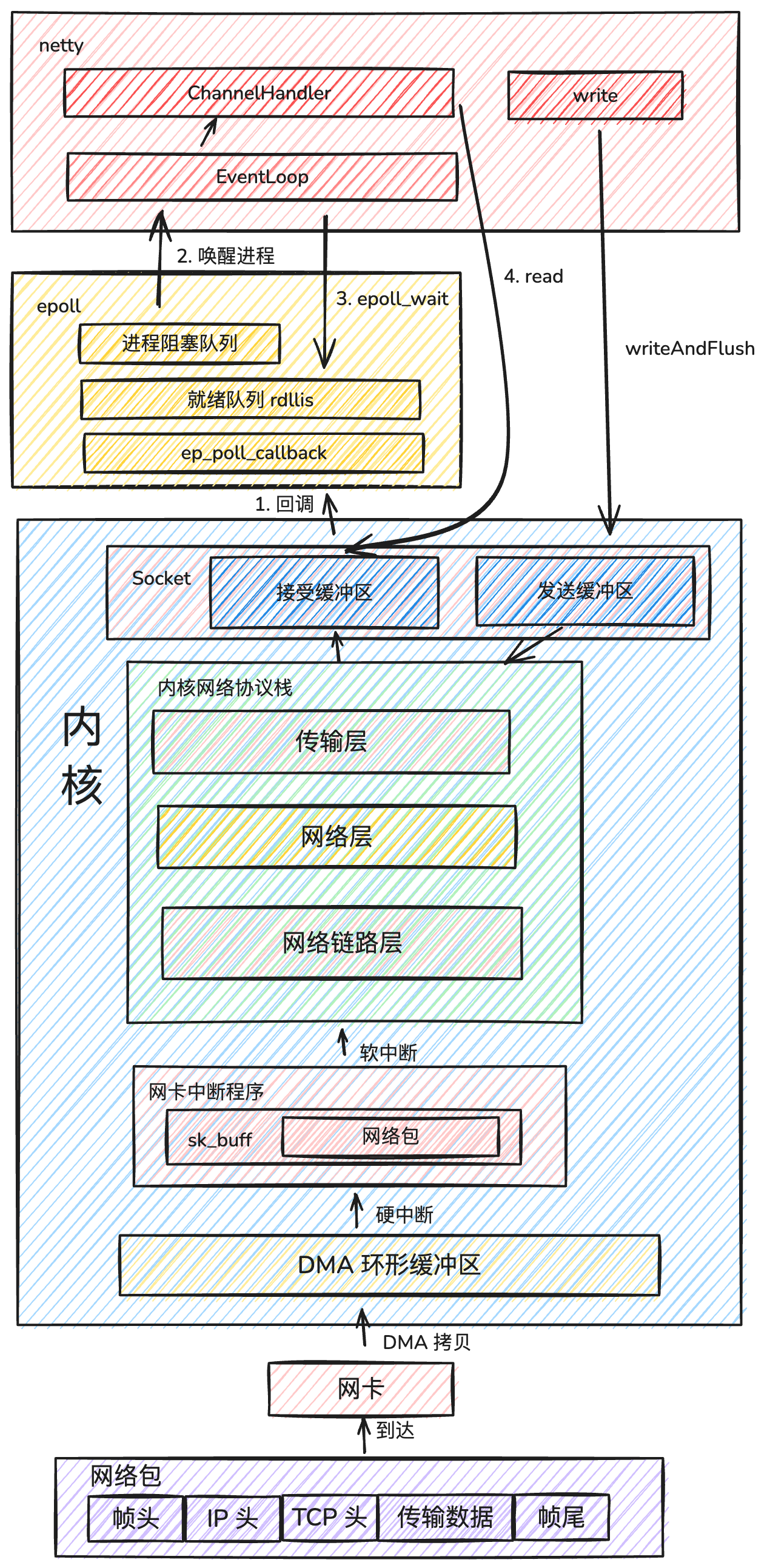
那么结合起来是什么情况呢?下面我们来看看Netty 接受网络数据完整的流程图:
epoll 的局限性
epoll 适合长连接场景,对于大量短连接的情况,如快速建立和断开的连接,epoll 需要频繁地添加和删除文件描述符,会导致系统调用的频率增加,增加内核负担。对于短连接密集型应用,可以考虑其他优化机制,如使用 SO_REUSEPORT 和负载均衡。
epoll 的事件管理依赖内核,而不能直接实现用户态通知。每次 I/O 都需要在内核态和用户态之间切换,而在频繁的 I/O 操作中,这种切换会带来额外的上下文切换开销。相比之下,io_uring 的设计尝试减少这种切换,通过提供更直接的 I/O 通道来提升效率。
再谈同步与异步
什么是同步?什么是异步?我们常常把它们的概念与阻塞与非阻塞相混淆。它们都会使程序“停下来”,下面我们来理清一下它们的概念。
同步和异步的区别主要在于任务的执行方式和程序是否需要等待结果。阻塞和非阻塞的区别在于调用方在等待结果时的状态。以 Java 中使用同步方法 socket.read() 为例,调用这个方法时,程序会等待直到数据读取完成后才继续执行下一行代码。这个“等待后继续执行下一行代码”,是同步,当前程序等待的状态,是阻塞。所以说,这是一个同步阻塞方法。经过前边对网络数据包接收流程的介绍,在这里我们可以将整个流程总结为两个阶段(图源bin的技术小屋微信公众号):
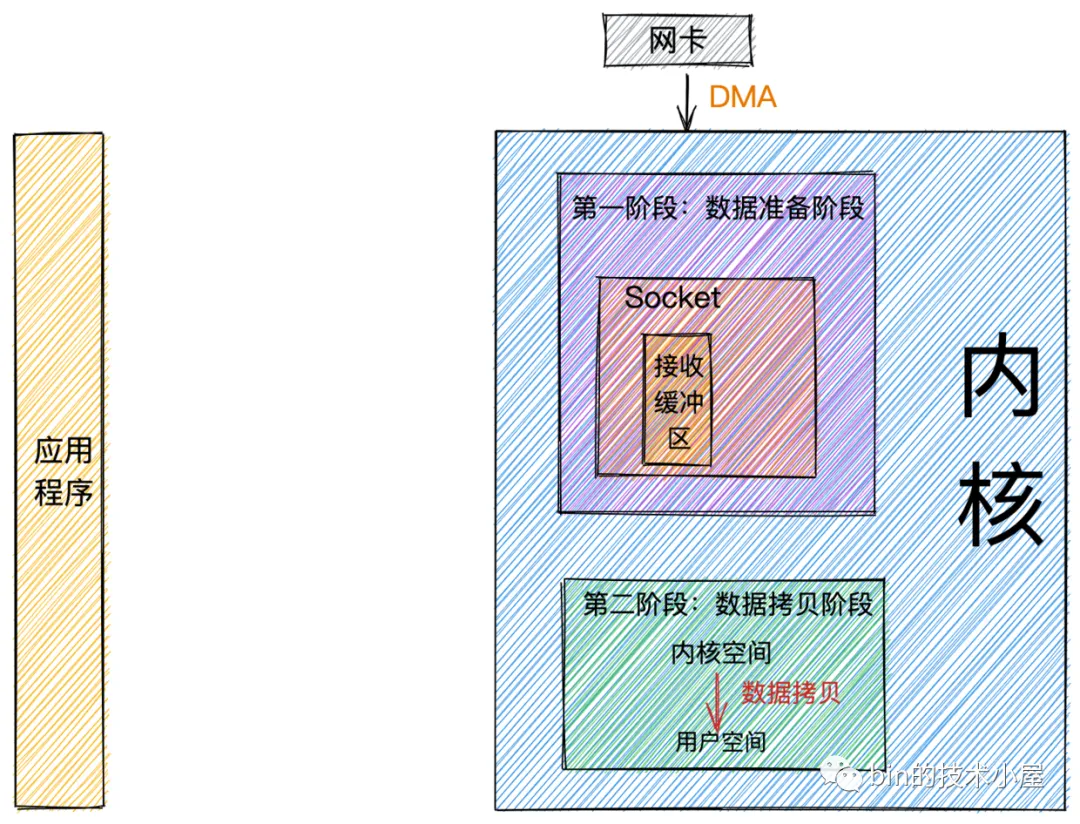
- 数据准备阶段: 在这个阶段,网络数据包到达网卡,通过DMA的方式将数据包拷贝到内存中,然后经过硬中断,软中断,接着通过内核线程ksoftirqd经过内核协议栈的处理,最终将数据发送到内核Socket的接收缓冲区中。
- 数据拷贝阶段: 当数据到达内核Socket的接收缓冲区中时,此时数据存在于内核空间中,需要将数据拷贝到用户空间中,才能够被应用程序读取。
阻塞和非阻塞
阻塞和非阻塞主要的区分是在第一阶段:数据准备阶段。
- 在第一阶段,当Socket的接收缓冲区中没有数据的时候,阻塞模式下应用线程会一直等待。非阻塞模式下应用线程不会等待,系统调用直接返回错误标志EWOULDBLOCK。
- 当Socket的接收缓冲区中有数据的时候,阻塞和非阻塞的表现是一样的,都会进入第二阶段等待数据从内核空间拷贝到用户空间,然后系统调用返回。
同步与异步
同步与异步主要的区别发生在第二阶段:数据拷贝阶段。
同步模式在数据准备好后,是由用户线程的内核态来执行第二阶段。所以应用程序会在第二阶段发生阻塞,直到数据从内核空间拷贝到用户空间,系统调用才会返回。Linux下的 epoll和Mac 下的 kqueue都属于同步 I/O。
异步模式下是由内核来执行第二阶段的数据拷贝操作,当内核执行完第二阶段,会通知用户线程I/O操作已经完成,并将数据回调给用户线程。所以在异步模式下 数据准备阶段和数据拷贝阶段均是由内核来完成,不会对应用程序造成任何阻塞。
Netty 的异步是什么?
Netty is an asynchronous event-driven network application framework
for rapid development of maintainable high performance protocol servers & clients. —— netty.io
Netty 是一个异步事件驱动的网络应用框架,这是 Netty 官网对于 Netty 的定义,但是根据我们对前面的分析,epoll 的多路复用技术是同步非阻塞的模式,获取就绪事件后需要同步调用 read 方法,将数据从内核空间拷贝到用户空间。那么 Netty 所说的“异步”是什么呢?
虽然 epoll 本身是同步的,但 Netty 将 epoll 调用封装在一个单独的 EventLoop 线程中,其他线程不会直接参与 epoll 调用过程。EventLoop 负责管理所有 I/O 操作,并利用 epoll 的 I/O 多路复用能力,在一个线程中监听多个 Channel 的事件。这样,epoll 的同步模型被限制在 EventLoop 内部,通过 ChannelFuture 对象和回调机制,使得程序不需要阻塞等待 I/O 操作的完成。每当一个异步操作(如写入数据或连接)被调用时,Netty 会立即返回一个 ChannelFuture,它可以注册回调函数,以便在 I/O 操作完成后执行。应用程序无需同步等待,而是通过 Future 或回调在事件完成时得到通知。实现了对 I/O 操作的异步管理。因此,Netty 是一个异步框架,而这种异步性并非依赖于 epoll 是否同步,而是框架本身的设计理念和运行机制使然。那么,除了这种“绕弯子”的异步,有没有真正的异步呢?
零拷贝在 I/O 方面的作用
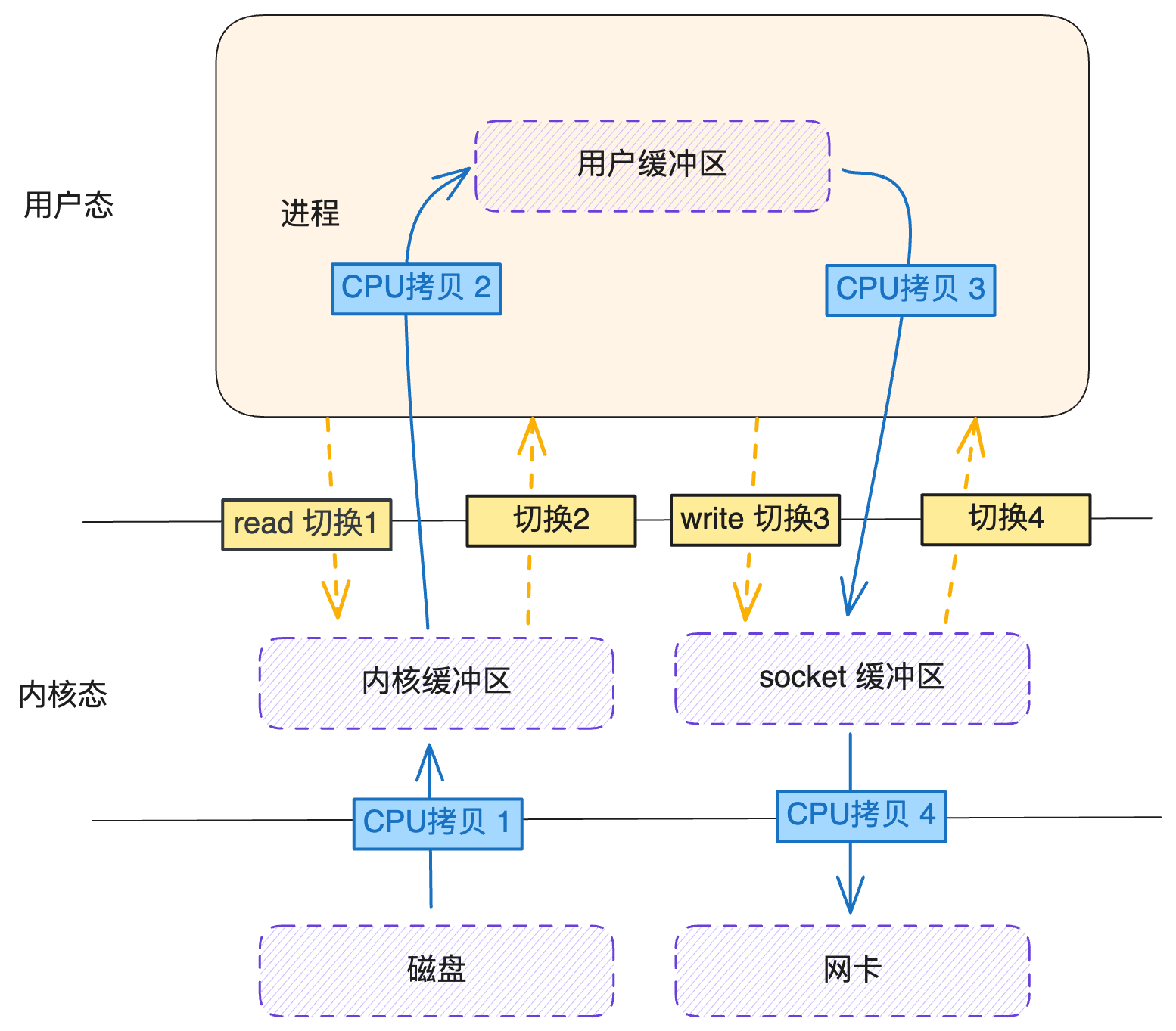
简单来说说零拷贝这个技术,当要将本地的数据发送到网络上时,传统的 I/O 流程,包括 read 和 write 的过程,
- read:把数据从磁盘读取到内核缓冲区,再拷贝到用户缓冲区。
- write:先把数据写入到socket缓冲区,最后写入网卡设备。
通常要进行 4 次上下文切换与 4 次 CPU 拷贝,如下图:
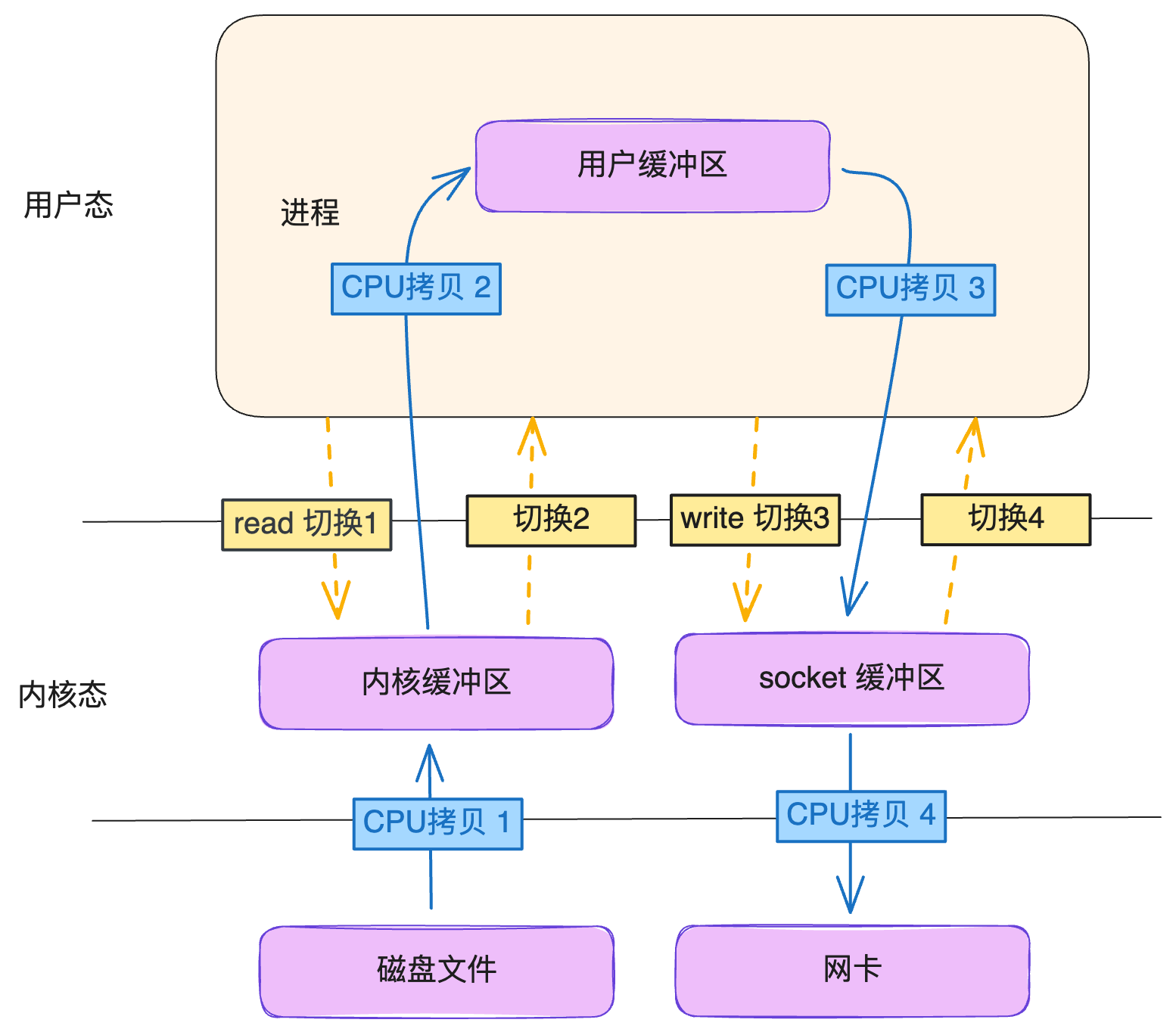
通过 DMA 技术,可以减少 2 次CPU拷贝,如下图(图源什么是零拷贝?):
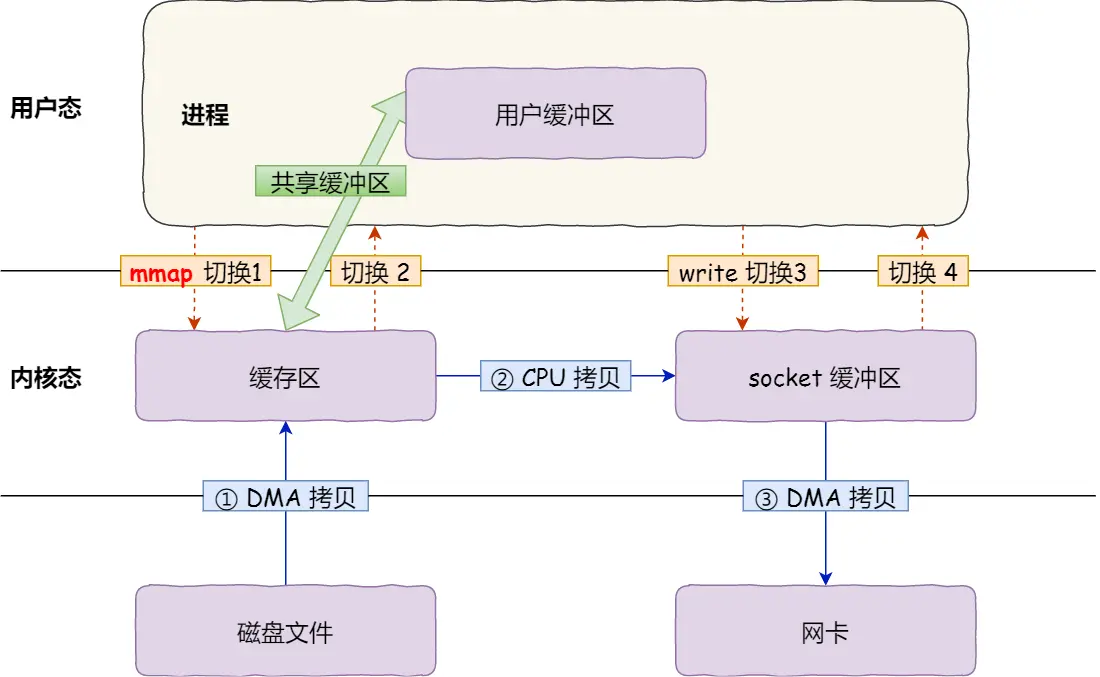
通过 mmap 技术,可以减少 1 次 CPU 拷贝,如下图(图源什么是零拷贝?):
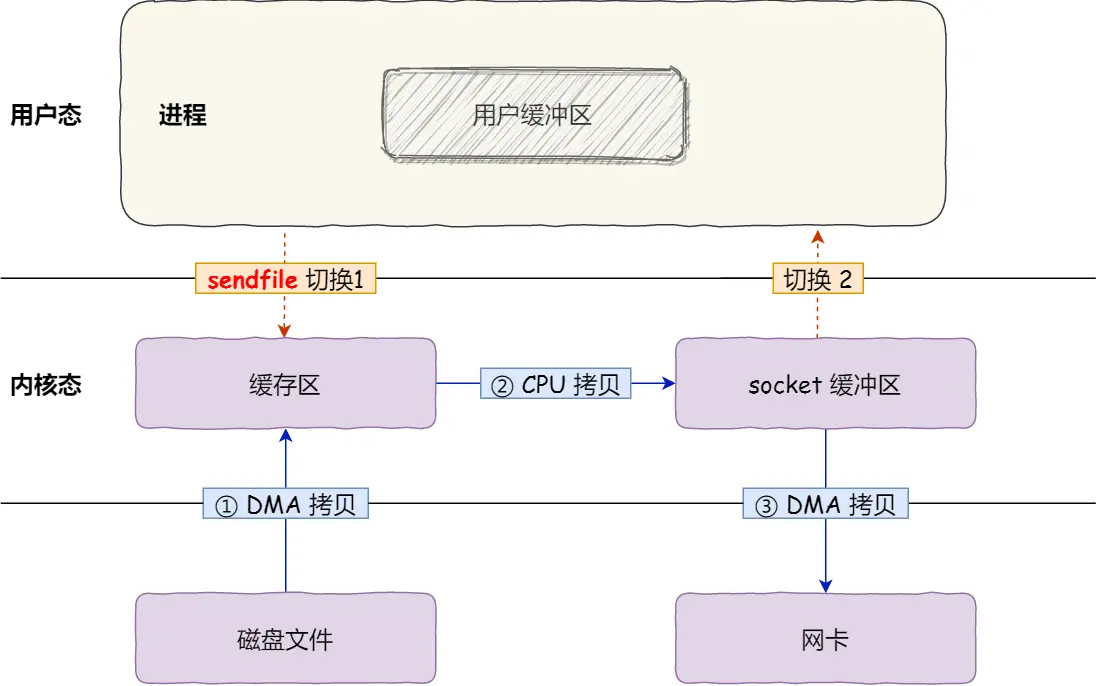
通过 sendfile 技术, 可以减少 1次上下文切换,如下图(图源什么是零拷贝?):
通过 SG-DMA 技术,可以减少 1 次CPU拷贝,如下图(图源什么是零拷贝?):
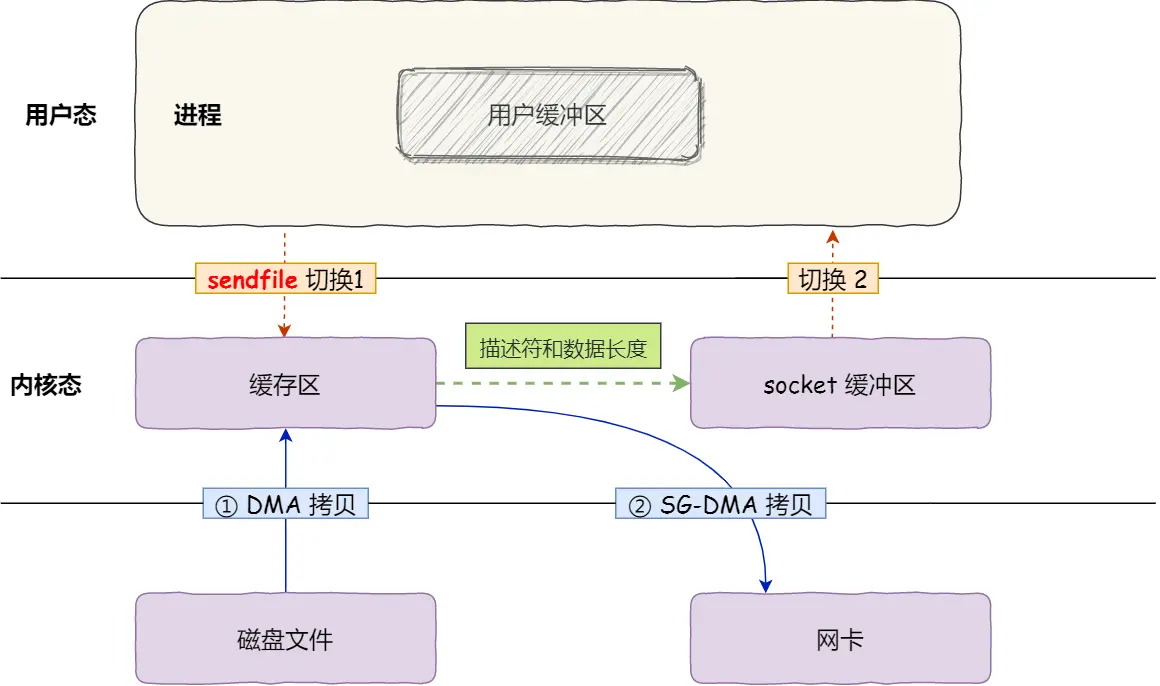
可以发现,sendfile+SG-DMA 实现的零拷贝,I/O发生了 2 次用户空间与内核空间的上下文切换,以及 2 次数据拷贝。其中 2 次数据拷贝都是包DMA拷贝。这就是真正的零拷贝(Zero-copy) 技术,全程都没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
io_uring 使用的是 mmap 零拷贝技术,通过共享同一内存地址来进行用户空间和内核空间的通信。
真正的异步:io_uring
介绍
io_uring 是 Linux 内核从 5.1 版本开始引入的一种高效异步 I/O 框架,旨在显著提高文件、网络等 I/O 操作的性能,为 I/O 操作提供了一种高效、真正异步的机制。
原理
io_uring 实现异步 I/O 的方式是一个生产者-消费者模型,通过 mmap 的方式共享内存区的环形队列(Ring Buffer),来实现用户空间与内核之间的高效通信。它主要分为两个环形队列:提交队列(Submission Queue,SQ):用于存放用户向内核提交的 I/O 请求,和完成队列(Completion Queue,CQ):用于存放内核处理完 I/O 请求后的完成信息。
用户进程和内核在这两个队列上分别操作,不需要频繁切换到内核态,避免了大量的上下文切换。
(1)用户进程生产 I/O 请求,放入 SQ。
(2)内核消费 SQ 中的 I/O 请求,完成后将结果放入完成队列 CQ。
(3)用户进程从 CQ 中收割I/O结果。
架构
io_uring 架构图(图源新一代异步IO框架 io_uring):
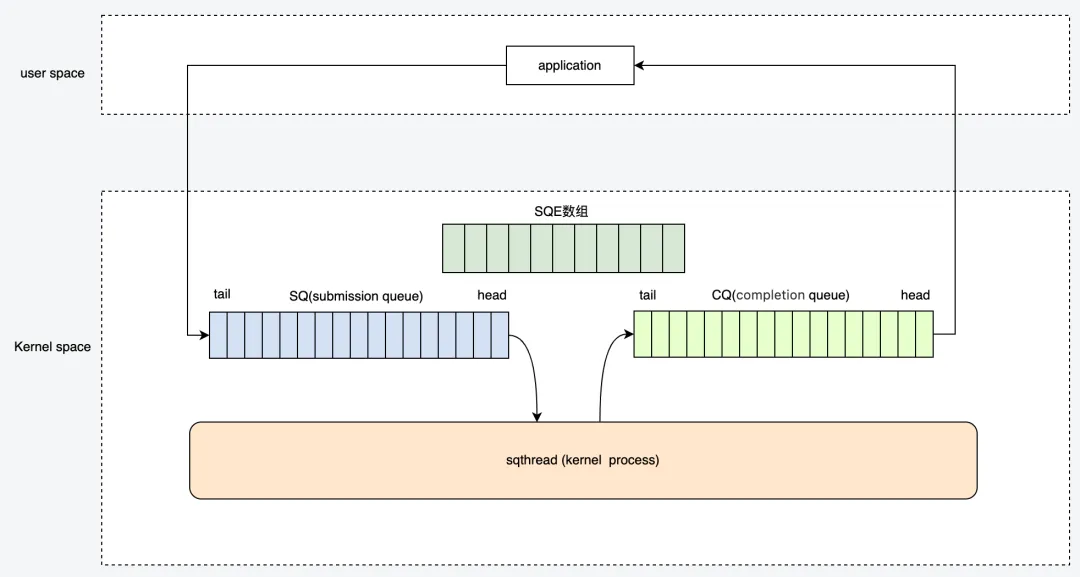
数据结构
SQE:提交队列条目(Submission Queue Entry),表示一个用户空间构造的 I/O 请求的具体条目。
SQ:提交队列(Submission Queue),用于存放 SQE 的环形缓冲区。
CQE:完成队列条目(Completion Queue Entry),用于存放一个 I/O 请求的处理结果。
CQ:完成队列(Completion Queue),用于存放 CQE 的环形缓冲区。
SQE aray:一个 SQE 数组,用于批量存放用户提交的 I/O 请求条目。
核心 API
io_uring 的实现仅仅使用了三个 syscall:io_uring_setup,io_uring_enter 和 io_uring_register。
-
io_uring_setup():用于初始化和配置 io_uring 。
-
io_uring_enter():用于提交和处理异步 I/O 操作。
-
io_uring_register():用于注册文件描述符、缓冲区、事件文件描述符等资源到 io_uring 环中。
操作 API
- io_uring_queue_init:初始化 io_uring 实例,准备好提交 I/O 请求。
- io_uring_get_sqe:获取一个 SQE。
- io_uring_prep_send:创建 send 请求,并配置相应的参数,如套接字描述符、数据缓冲区和数据长度。
- io_uring_prep_recv:创建 recv 请求,需要指定接收数据的缓冲区、套接字描述符和缓冲区长度。
- io_uring_submit:提交 I/O 请求到 io_uring,请求会在后台进行。
- io_uring_wait_cqe:阻塞等待 I/O 完成。
- io_uring_cqe_seen:标记 CQE 为已处理。
函数簇
io_uring_prep_* 是一组函数,用户调用它们来配置不同类型的 I/O 操作,比如读取、写入、连接、接收、发送等。这些函数不会实际执行 I/O 操作,只是将操作的详细信息填充到 SQE 中,准备提交给内核。以下是一些常用的 io_uring_prep_* 函数及其用途:
| 函数名 | 用途 |
|---|---|
| io_uring_prep_nop | 准备一个 NOP(无操作)请求,用于测试或同步。 |
| io_uring_prep_read | 准备一个 文件读取请求。 |
| io_uring_prep_write | 准备一个 文件写入请求。 |
| io_uring_prep_readv | 准备一个 分散读取请求(读到多个缓冲区)。 |
| io_uring_prep_writev | 准备一个 聚集写入请求(从多个缓冲区写出)。 |
| io_uring_prep_send | 准备一个 发送数据请求(用于网络套接字)。 |
| io_uring_prep_recv | 准备一个 接收数据请求(用于网络套接字)。 |
| io_uring_prep_accept | 准备一个 接受新连接请求(用于监听套接字)。 |
| io_uring_prep_connect | 准备一个 连接请求(用于发起网络连接)。 |
| io_uring_prep_close | 准备一个 关闭文件描述符请求。 |
liburing
io_uring 的核心系统调用只有三个,但使用起来较为复杂,io_uring 的实现者 Jens Axboe 在 io_uring 之上封装了新的 liburing 库,用于简化在 Linux 系统 io_uring 的开发。
// 用户初始化 io_uring。该方法中包含了内存空间的初始化以及mmap 调用,entries:队列深度
int io_uring_queue_init(unsigned entries, struct io_uring *ring, unsigned flags);
// 为了提交IO请求,需要获取里面queue的一个空闲项
struct io_uring_sqe *io_uring_get_sqe(struct io_uring *ring);
// 非系统调用,准备阶段,和libaio封装的io_prep_writev一样
void io_uring_prep_writev(struct io_uring_sqe *sqe, int fd,const struct iovec *iovecs, unsigned nr_vecs, off_t offset)
// 非系统调用,准备阶段,和libaio封装的io_prep_readv一样
void io_uring_prep_readv(struct io_uring_sqe *sqe, int fd, const struct iovec *iovecs, unsigned nr_vecs, off_t offset)
// 提交sq的entry,不会阻塞等到其完成,内核在其完成后会自动将sqe的偏移信息加入到cq,在提交时需要加锁
int io_uring_submit(struct io_uring *ring);
// 提交sq的entry,阻塞等到其完成,在提交时需要加锁。
int io_uring_submit_and_wait(struct io_uring *ring, unsigned wait_nr);
// 非系统调用 遍历时,可以获取cqe的data
void *io_uring_cqe_get_data(const struct io_uring_cqe *cqe)
// 清理io_uring
void io_uring_queue_exit(struct io_uring *ring);
工作流程
工作流程的案例
使用 io_uring 进行 Socket 网络数据包的收发流程,下面是其工作流程和用户态与内核态交互的详细步骤。
1. 准备 I/O 请求:用户进程在 SQE(提交队列条目)中构造 I/O 请求,将请求放入提交队列。每个请求包含了操作类型、目标文件描述符、缓冲区地址等信息。
2. 提交 I/O 请求:用户通过 io_uring_enter() 系统调用通知内核处理队列中的请求。io_uring_enter() 系统调用的设计尽量做到批量提交,以减少系统调用的次数。
3. 内核处理请求:内核从提交队列读取请求并执行相应的 I/O 操作(如读、写),并将处理结果写入完成队列。
4. 获取 I/O 完成结果:用户进程在完成队列中读取完成信息,不需要系统调用即可访问完成的 I/O 请求结果。
案例的核心代码
-
初始化 io_uring:
// 初始化 io_uring io_uring_queue_init(256, &ring, 0); -
创建 Socket:
// 创建服务端 Socket int server_fd = socket(AF_INET, SOCK_STREAM, 0); if (server_fd < 0) { perror("Socket creation failed"); exit(1); } // 绑定地址 memset(&server_addr, 0, sizeof(server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = INADDR_ANY; server_addr.sin_port = htons(PORT); bind(server_fd, (struct sockaddr *)&server_addr, sizeof(server_addr)); // 开始监听 listen(server_fd, BACKLOG); printf("Server listening on port %d\n", PORT); // 接受客户端连接 int client_fd = accept(server_fd, (struct sockaddr *)&client_addr, &client_len); if (client_fd < 0) { perror("Accept failed"); exit(1); } -
socket 绑定 io_uring
// 异步接收数据 struct io_uring_sqe *sqe = io_uring_get_sqe(&ring); io_uring_prep_recv(sqe, client_fd, buffer, BUFFER_SIZE, 0); io_uring_sqe_set_data(sqe, buffer); io_uring_submit(&ring); -
等待完成队列:
// 等待接收完成 struct io_uring_cqe *cqe; io_uring_wait_cqe(&ring, &cqe); -
处理结果:
// 处理接收数据 printf("Received: %s\n", (char *)io_uring_cqe_get_data(cqe)); io_uring_cqe_seen(&ring, cqe); -
发送响应
// 异步发送响应 const char *response = "Hello from io_uring server!\n"; sqe = io_uring_get_sqe(&ring); io_uring_prep_send(sqe, client_fd, response, strlen(response), 0); io_uring_sqe_set_data(sqe, NULL); io_uring_submit(&ring); -
清理资源:
// 清理 close(client_fd); close(server_fd); io_uring_queue_exit(&ring);
完整代码如下:
int main() {
struct io_uring ring;
struct sockaddr_in server_addr, client_addr;
socklen_t client_len = sizeof(client_addr);
char buffer[BUFFER_SIZE];
// 初始化 io_uring
io_uring_queue_init(256, &ring, 0);
// 创建服务端 Socket
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd < 0) {
perror("Socket creation failed");
exit(1);
}
// 绑定地址
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(PORT);
bind(server_fd, (struct sockaddr *)&server_addr, sizeof(server_addr));
// 开始监听
listen(server_fd, BACKLOG);
printf("Server listening on port %d\n", PORT);
// 接受客户端连接
int client_fd = accept(server_fd, (struct sockaddr *)&client_addr, &client_len);
if (client_fd < 0) {
perror("Accept failed");
exit(1);
}
printf("Client connected\n");
// 异步接收数据
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
io_uring_prep_recv(sqe, client_fd, buffer, BUFFER_SIZE, 0);
io_uring_sqe_set_data(sqe, buffer);
io_uring_submit(&ring);
// 等待接收完成
struct io_uring_cqe *cqe;
io_uring_wait_cqe(&ring, &cqe);
// 处理接收数据
printf("Received: %s\n", (char *)io_uring_cqe_get_data(cqe));
io_uring_cqe_seen(&ring, cqe);
// 异步发送响应
const char *response = "Hello from io_uring server!\n";
sqe = io_uring_get_sqe(&ring);
io_uring_prep_send(sqe, client_fd, response, strlen(response), 0);
io_uring_sqe_set_data(sqe, NULL);
io_uring_submit(&ring);
io_uring_wait_cqe(&ring, &cqe);
io_uring_cqe_seen(&ring, cqe);
// 清理
close(client_fd);
close(server_fd);
io_uring_queue_exit(&ring);
return 0;
}
工作模式
i_uring 有Polling 和 非 Polling 两种工作模式,现在我们来一一介绍。
io_uring 的工作模式主要涉及 用户态与内核态的交互方式,以及 完成队列 (CQ) 的处理机制。它的灵活性允许用户根据性能需求选择不同的模式。这些模式主要体现在请求的提交和完成处理方式上。
非 Polling 模式(默认模式)
工作流程:适合轻量级任务。
1. 用户通过 io_uring_submit() 提交请求。
2. 内核完成 I/O 操作后,通过中断通知用户态完成队列中有结果。
3. 用户调用 io_uring_wait_cqe() 等待完成队列事件,或通过非阻塞方式轮询获取完成事件。
代码示例:
int main() {
struct io_uring ring;
io_uring_queue_init(8, &ring, 0); // 非 Polling 模式
int fd = open("example.txt", O_RDONLY);
char buffer[128];
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
io_uring_prep_read(sqe, fd, buffer, sizeof(buffer), 0); // 准备读取请求
io_uring_submit(&ring); // 提交请求
struct io_uring_cqe *cqe;
io_uring_wait_cqe(&ring, &cqe); // 阻塞等待完成
if (cqe->res >= 0) {
printf("Read %d bytes: %s\n", cqe->res, buffer);
}
io_uring_cqe_seen(&ring, cqe);
close(fd);
io_uring_queue_exit(&ring);
return 0;
}
Polling 模式
内核轮询模式:适合极端高并发和高吞吐场景。
工作流程
1. 用户启用 IORING_SETUP_SQPOLL 标志,内核启动一个专用线程轮询提交队列。
2. 提交操作变得几乎是零开销,因为不需要通过系统调用通知内核。
3. 内核轮询完成队列,减少中断和上下文切换。
代码示例:
int main() {
struct io_uring_params params = {0};
params.flags = IORING_SETUP_SQPOLL; // 启用内核轮询
params.sq_thread_cpu = 1; // 指定轮询线程的 CPU 核
params.sq_thread_idle = 1000; // 线程空闲超时时间
struct io_uring ring;
io_uring_queue_init_params(8, &ring, ¶ms);
int fd = open("example.txt", O_RDONLY);
char buffer[128];
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
io_uring_prep_read(sqe, fd, buffer, sizeof(buffer), 0);
io_uring_submit(&ring);
struct io_uring_cqe *cqe;
io_uring_wait_cqe(&ring, &cqe);
if (cqe->res >= 0) {
printf("Read %d bytes: %s\n", cqe->res, buffer);
}
io_uring_cqe_seen(&ring, cqe);
close(fd);
io_uring_queue_exit(&ring);
return 0;
}
用户轮询模式:适合对延迟敏感的任务。
工作流程
- 用户启用 IORING_SETUP_IOPOLL 标志。
- 用户通过 io_uring_peek_cqe() 或 io_uring_wait_cqe_timeout 不断轮询完成队列,而非等待中断通知。
代码示例:
int main() {
struct io_uring_params params = {0};
params.flags = IORING_SETUP_IOPOLL; // 启用用户态轮询
struct io_uring ring;
io_uring_queue_init_params(8, &ring, ¶ms);
int fd = open("example.txt", O_RDONLY);
char buffer[128];
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
io_uring_prep_read(sqe, fd, buffer, sizeof(buffer), 0);
io_uring_submit(&ring);
struct io_uring_cqe *cqe;
while (io_uring_peek_cqe(&ring, &cqe) != 0) {
// 轮询 CQE,非阻塞等待
}
if (cqe->res >= 0) {
printf("Read %d bytes: %s\n", cqe->res, buffer);
}
io_uring_cqe_seen(&ring, cqe);
close(fd);
io_uring_queue_exit(&ring);
return 0;
}
Direct I/O 模式
Direct I/O 是一种绕过操作系统缓存层的 I/O 模式。io_uring 可以通过 IORING_SETUP_IOPOLL 标志启用 Direct I/O 模式。这种模式有以下特点:
-
特点:直接将 I/O 请求发送到块设备,不经过内核的页缓存(Page Cache);要求目标设备支持 Direct I/O 操作。
-
使用场景:数据库(如 MySQL、PostgreSQL 等)通常利用 Direct I/O 来管理自己的缓存;延迟敏感型任务(如日志写入或分析工具)。
代码示例:
#define BLOCK_SIZE 4096 // 块大小,必须与设备对齐
void error_exit(const char *msg) {
perror(msg);
exit(EXIT_FAILURE);
}
int main() {
struct io_uring ring;
struct io_uring_params params = {0};
// 设置用户态轮询模式 (IOPOLL)
params.flags = IORING_SETUP_IOPOLL;
// 初始化 io_uring
if (io_uring_queue_init_params(8, &ring, ¶ms) < 0) {
error_exit("io_uring initialization failed");
}
// 打开块设备文件(以 Direct I/O 模式打开)
int fd = open("/dev/sda", O_DIRECT | O_RDONLY);
if (fd < 0) {
error_exit("Failed to open block device");
}
// 分配对齐的缓冲区
void *buffer;
if (posix_memalign(&buffer, BLOCK_SIZE, BLOCK_SIZE)) {
error_exit("Failed to allocate aligned buffer");
}
memset(buffer, 0, BLOCK_SIZE);
// 准备 I/O 请求
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
io_uring_prep_read(sqe, fd, buffer, BLOCK_SIZE, 0); // 从块设备的偏移 0 开始读取
io_uring_submit(&ring);
// 等待完成
struct io_uring_cqe *cqe;
if (io_uring_wait_cqe(&ring, &cqe) < 0) {
error_exit("Failed to wait for CQE");
}
if (cqe->res >= 0) {
printf("Read %d bytes from block device\n", cqe->res);
} else {
printf("I/O failed with error %d\n", cqe->res);
}
// 清理资源
io_uring_cqe_seen(&ring, cqe);
free(buffer);
close(fd);
io_uring_queue_exit(&ring);
return 0;
}
总结如下:
| 模式 | 描述 | 适用场景 |
|---|---|---|
| 标准 I/O 模式 | 默认模式,依赖内核缓存(Page Cache)。 | 普通文件 I/O,低并发或轻量任务。 |
| Direct I/O 模式 | 绕过页缓存,直接与块设备交互,需要设备支持和对齐。 | 数据库、日志写入、大规模文件传输。 |
| 用户态轮询模式 | 用户态直接轮询完成队列,减少上下文切换和中断延迟。 | 延迟敏感的高性能场景。 |
| 内核态轮询模式 | 内核轮询提交队列,减少系统调用开销,适合极端高并发任务。 | 极端性能需求,例如 Web 服务器或消息队列。 |
样例
io_uring 服务端
完整的 io_uring 服务端如下:
#include <liburing.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <fcntl.h>
#define PORT 12345
#define BUFFER_SIZE 1024
#define BACKLOG 128
enum {
ACCEPT,
READ,
WRITE
};
struct io_data {
int fd;
int type;
char buffer[BUFFER_SIZE];
};
void error_exit(const char *message) {
perror(message);
exit(EXIT_FAILURE);
}
// 创建和绑定 Socket
int create_and_bind_socket() {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
error_exit("Socket creation failed");
}
int opt = 1;
if (setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt)) < 0) {
error_exit("Set socket options failed");
}
struct sockaddr_in addr = {
.sin_family = AF_INET,
.sin_addr.s_addr = htonl(INADDR_ANY),
.sin_port = htons(PORT)
};
if (bind(sockfd, (struct sockaddr *)&addr, sizeof(addr)) < 0) {
error_exit("Bind failed");
}
if (listen(sockfd, BACKLOG) < 0) {
error_exit("Listen failed");
}
return sockfd;
}
// 使用 io_uring 接受连接
void prepare_accept(struct io_uring *ring, int sockfd) {
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
if (!sqe) {
fprintf(stderr, "Failed to get SQE for accept\n");
return;
}
struct io_data *data = malloc(sizeof(*data));
data->fd = sockfd;
data->type = ACCEPT;
io_uring_prep_accept(sqe, sockfd, NULL, NULL, 0);
io_uring_sqe_set_data(sqe, data);
io_uring_submit(ring);
}
// 接收数据
void prepare_recv(struct io_uring *ring, struct io_data *data) {
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
if (!sqe) {
fprintf(stderr, "Failed to get SQE for recv\n");
return;
}
memset(data->buffer, 0, BUFFER_SIZE);
data->type = READ;
io_uring_prep_recv(sqe, data->fd, data->buffer, BUFFER_SIZE - 1, 0);
io_uring_sqe_set_data(sqe, data);
io_uring_submit(ring);
}
void remove_newline(char *str) {
str[strcspn(str, "\n")] = '\0'; // 替换换行符为结束符
}
// 发送数据
void prepare_send(struct io_uring *ring, struct io_data *data, const char *response) {
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
if (!sqe) {
fprintf(stderr, "Failed to get SQE for send\n");
return;
}
char *result = malloc(BUFFER_SIZE);
remove_newline((char *)response);
snprintf(result, BUFFER_SIZE, "Server Response: [You said: %s]\n", response);
data->type = WRITE;
memcpy(data->buffer, result, strlen(result) + 1);
io_uring_prep_send(sqe, data->fd, result, strlen(data->buffer), 0);
io_uring_sqe_set_data(sqe, data);
io_uring_submit(ring);
}
// 处理完成队列事件
void handle_cqe(struct io_uring *ring, struct io_uring_cqe *cqe) {
struct io_data *data = io_uring_cqe_get_data(cqe);
if (!data) {
io_uring_cqe_seen(ring, cqe);
return;
}
if (cqe->res <= 0) {
// 客户端关闭或发生错误
close(data->fd);
free(data);
} else if (data->type == ACCEPT) {
// 新连接
int client_fd = cqe->res;
// New connection accepted: 5
printf("New connection accepted: %d\n", client_fd);
struct io_data *client_data = malloc(sizeof(*client_data));
client_data->fd = client_fd;
prepare_recv(ring, client_data);
// 继续接受新连接
prepare_accept(ring, data->fd);
free(data);
} else if (data->type == READ) {
// 处理接收到的数据
data->buffer[cqe->res] = '\0'; // 确保字符串终止
// Received: Hello huangxuwei
printf("Received: %s", data->buffer);
// 准备发送响应
prepare_send(ring, data, data->buffer);
} else if (data->type == WRITE) {
// 准备接收新数据
prepare_recv(ring, data);
}
io_uring_cqe_seen(ring, cqe);
}
int main() {
int sockfd = create_and_bind_socket();
printf("Listening on port %d...\n", PORT);
struct io_uring ring;
if (io_uring_queue_init(32, &ring, 0) < 0) {
error_exit("io_uring initialization failed");
}
prepare_accept(&ring, sockfd);
while (1) {
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(&ring, &cqe);
if (ret < 0) {
error_exit("io_uring_wait_cqe failed");
}
handle_cqe(&ring, cqe);
}
io_uring_queue_exit(&ring);
close(sockfd);
return 0;
}
io_uring 客户端
客户端使用 nc 工具,命令如下:
echo "Hello Server!" | nc 127.0.0.1 12345
服务端响应:
New connection accepted: 4
Received: Hello Server!
epoll 对比 io_uring
同步与异步的核心区别是谁把数据从内核空间拷贝到了用户空间,io_uring 通过 mmap 实现了内核缓冲区到用户内存的映射,从而使用户不需到内核拷贝数据,实现了异步 I/O。但是为什么 epoll 不把就绪事件里的数据也通过mmap 映射到用户态的?不也能减少这次数据拷贝吗?接下来详细说说。
内核与用户空间的数据拷贝
具体来说:
-
同步I/O:应用程序会阻塞,直到数据已经完全从内核态拷贝到用户态。整个数据的传输过程是同步进行的,应用程序必须等待I/O操作完成。
-
异步I/O:应用程序发起I/O操作后不需要等待数据完成传输,内核会异步完成I/O操作并通知应用程序。应用程序无需阻塞等待。
为什么 epoll 没有使用 mmap?
io_uring 的设计目标就是为了减少内核和用户态之间的切换和数据拷贝。通过 mmap,它允许应用程序直接访问内核的环形缓冲区(ring buffer),从而减少内核与用户空间的交互。而 epoll 仅处理事件通知,即通知某个文件描述符是否可读/可写,它并不直接处理数据的传输。
- epoll 的设计目标:epoll 是一个事件驱动的机制,只负责通知应用程序哪个文件描述符上有 I/O 事件需要处理,而不负责数据传输。它的工作是在用户态和内核态之间传递事件通知,而不是传递数据,处理数据本身的工作仍然由 read 或 write 等系统调用来完成。因此,epoll 的通知信息本质上很小,mmap 在这里没有明显的优势。
- io_uring 的设计目标:io_uring 通过 mmap 提供了一种机制,使得用户空间可以直接访问内核的 I/O 队列,从而减少不必要的系统调用。这种设计能够将 I/O 请求和完成的结果传递到用户态,无需应用程序再次调用 read 或 write。通过 mmap,io_uring 可以在内核缓冲区和用户态之间进行高效的 I/O 操作,而不需要额外的拷贝和上下文切换。
I/O 模型的发展
总结一下 I/O 模型的发展如下:
- NIO:通过不断轮训发起系统调用,看是否有数据到达内核,有数据的话,再将数据从内核拷贝到用户态
- select:用户不去轮训发起系统调用,而是内核发起系统调用去轮训数据,有数据的话返回给用户态。(全部连接)
- poll:优化了 select 的数据结构,改为了动态数组。(全部连接)
- epoll:通过事件通知+回调的方式优化了 poll 与 select,通知用户态已经有数据到内核了,去拷贝数据到用户态。(读写事件连接)
- io_uring:通过 mmap 零拷贝优化了将数据从内核空间拷贝到用户空间的开销。
io_uring 在 RPC 框架中的使用
在 Java 中使用 io_uring
文章的开头提到,Netty 团队已经开始孵化关于 io_uring 的项目 —— netty-incubator-transport-io_uring,下面让我们看一看,Netty 是怎么将 io_uring 引入到 Netty 框架中来的。
Netty 使用 io.netty.incubator.channel.uring.Native 类封装了 io_uring 底层的 C 接口,使整个项目可以调用函数,比如 io_uring_setup 的调用链如下:
Java 语言部分:
io.netty.incubator.channel.uring.Native#createRingBuffer(int, int)
io.netty.incubator.channel.uring.Native#ioUringSetup
C 语言部分:
static const JNINativeMethod method_table[] = {
{"ioUringSetup", "(I)[[J", (void *) netty_io_uring_setup},{}}
netty_io_uring_native.c:240/netty_io_uring_setup
syscall.h:25/sys_io_uring_setup
syscall.c:34/sys_io_uring_setup
开发案例
@Data
@Slf4j
@Service("EchoIOUringServer")
public class EchoIOUringServer {
// 服务器端口
@Value("${server.port}")
private int port;
// 通过nio方式来接收连接和处理连接
private EventLoopGroup bg;
private EventLoopGroup wg;
// 启动引导器
private ServerBootstrap b = new ServerBootstrap();
public void run() {
//连接监听线程组
bg = new IOUringEventLoopGroup(1);
//传输处理线程组
wg = new IOUringEventLoopGroup(1);
try {
//1 设置reactor 线程
b.group(bg, wg);
//2 设置nio类型的channel
b.channel(IOUringServerSocketChannel.class);
//3 设置监听端口
b.localAddress(new InetSocketAddress(port));
//4 设置通道选项
// b.option(ChannelOption.SO_KEEPALIVE, true);
b.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
b.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
//5 装配流水线
b.childHandler(new ChannelInitializer<SocketChannel>() {
//有连接到达时会创建一个channel
protected void initChannel(SocketChannel ch) throws Exception {
// 管理pipeline中的Handler
ch.pipeline().addLast(NettyEchoServerHandler.INSTANCE);
}
});
// 6 开始绑定server
// 通过调用sync同步方法阻塞直到绑定成功
ChannelFuture channelFuture = b.bind().sync();
log.info(
"疯狂创客圈 EchoIOUringServer 服务启动, 端口 " +
channelFuture.channel().localAddress());
// 7 监听通道关闭事件
// 应用程序会一直等待,直到channel关闭
ChannelFuture closeFuture =
channelFuture.channel().closeFuture();
closeFuture.sync();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 8 优雅关闭EventLoopGroup,
// 释放掉所有资源包括创建的线程
wg.shutdownGracefully();
bg.shutdownGracefully();
}
}
}
从 Netty 官方给的这个例子来看,io_uring 的使用方式与 epoll 一样,初步来看线程模型也是一样的,io_uring 的具体逻辑都封装在了 IOUringEventLoopGroup 和 IOUringServerSocketChannel 中。
IOUringEventLoop 的事件循环
@Override
protected void run() {
final IOUringCompletionQueue completionQueue = ringBuffer.ioUringCompletionQueue();
final IOUringSubmissionQueue submissionQueue = ringBuffer.ioUringSubmissionQueue();
// Lets add the eventfd related events before starting to do any real work.
addEventFdRead(submissionQueue);
for (;;) {
try {
logger.trace("Run IOUringEventLoop {}", this);
// Prepare to block wait
long curDeadlineNanos = nextScheduledTaskDeadlineNanos();
if (curDeadlineNanos == -1L) {
curDeadlineNanos = NONE; // nothing on the calendar
}
nextWakeupNanos.set(curDeadlineNanos);
// Only submit a timeout if there are no tasks to process and do a blocking operation
// on the completionQueue.
try {
if (!hasTasks()) {
if (curDeadlineNanos != prevDeadlineNanos) {
prevDeadlineNanos = curDeadlineNanos;
submissionQueue.addTimeout(deadlineToDelayNanos(curDeadlineNanos), (short) 0);
}
// Check there were any completion events to process
if (!completionQueue.hasCompletions()) {
// Block if there is nothing to process after this try again to call process(....)
logger.trace("submitAndWait {}", this);
submissionQueue.submitAndWait();
}
}
} finally {
if (nextWakeupNanos.get() == AWAKE || nextWakeupNanos.getAndSet(AWAKE) == AWAKE) {
pendingWakeup = true;
}
}
} catch (Throwable t) {
handleLoopException(t);
}
// Avoid blocking for as long as possible - loop until available work exhausted
boolean maybeMoreWork = true;
do {
try {
// CQE processing can produce tasks, and new CQEs could arrive while
// processing tasks. So run both on every iteration and break when
// they both report that nothing was done (| means always run both).
maybeMoreWork = completionQueue.process(this) != 0 | runAllTasks();
} catch (Throwable t) {
handleLoopException(t);
}
// Always handle shutdown even if the loop processing threw an exception
try {
if (isShuttingDown()) {
closeAll();
if (confirmShutdown()) {
return;
}
if (!maybeMoreWork) {
maybeMoreWork = hasTasks() || completionQueue.hasCompletions();
}
}
} catch (Throwable t) {
handleLoopException(t);
}
} while (maybeMoreWork);
}
}
先交代两个非主干逻辑的细节:
- addEventFdRead(submissionQueue) 将 eventfd 的读操作提交 io_uring,其作用主要用于唤醒事件循环线程。由于 submissionQueue.submitAndWait() 这一步是阻塞的,想要唤醒事件循环,向 eventfd 执行一个写操作即可。
- submissionQueue.addTimeout(deadlineToDelayNanos(curDeadlineNanos), (short) 0) 用于处理延迟执行的任务,可以暂且忽略。
搞清楚上述两个细节,主干流程就很清晰了:
- submissionQueue.submitAndWait() 提交任务,等待至少一个任务完成;
- completionQueue.process(callback) 处理已经完成的任务,回调方法也就是 void handle(int fd, int res, int flags, byte op, short data);
- 最后就是向 submissionQueue 添加任务,原来的epoll 模型是,epoll_wait 等待就绪事件,然后执行相关的 IO 系统调用;
Netty 当前的实现并没为 io_uring 设置任何 flag,使用默认中断模式, 没有使用内核轮询模式,前面的三种模式的介绍到:中断模式是性能最差的一种。
在 RPC 中使用 io_uring
palmx 是一个笔者基于 Netty 开发的次世代高性能 RPC 框架,在底层的 IO 模块支持了 io_uring,支持的步骤如下:。
- 添加 io_uring 依赖:
<dependency>
<groupId>io.netty.incubator</groupId>
<artifactId>netty-incubator-transport-native-io_uring</artifactId>
<version>0.0.25.Final</version>
</dependency>
注意*:本框架为实验性质的 RPC 学习框架,引入 incubator 孵化包不会应用于生产环境,生产环境谨慎使用 incubator 包或者项目。
- 使用 iOUringDatagramChannel
public static Class<? extends Channel> getChannelClass() {
boolean iOUringAvailable = IOUring.isAvailable();
boolean ioUringEnable = PalmxConfig.getIoUringEnable();
if (iOUringAvailable && ioUringEnable) {
return IOUringDatagramChannel.class;
}
log.info("get iOUringDatagramChannel fail, available = {} , enable = {}", iOUringAvailable, ioUringEnable);
return NioDatagramChannel.class;
}
如果需要使用 palmx,可以参考样例例:palmx-samples
为什么是未来的系统调用?
io_uring 极大地提升了 I/O 操作的性能和灵活性,理论上,io_uring 可以支持异步化的几乎所有系统调用,因此有观点认为可以“基于 io_uring 重写所有系统调用”。io_uring 提供了一个高效的事件驱动模型,使得大量系统调用不再局限于阻塞或同步模型,带来了许多潜在的优化可能性。
io_uring 可以支持重写几乎所有系统调用
- 通用的异步接口:io_uring 的设计不仅局限于传统的 I/O 操作,而是提供了一种通用的机制,使任何系统调用都能以异步方式运行,通过 io_uring 提供的 IORING_OP 操作集,开发者可以对文件描述符、网络套接字、设备文件等资源进行异步操作。
- 高效的用户态与内核态通信:io_uring 通过 共享内存区和环形缓冲区实现了用户态和内核态之间的高效通信。应用程序可以直接将系统调用请求写入 io_uring 的提交队列,内核处理完后将结果写入完成队列。减少了用户态与内核态之间的上下文切换,提升了 I/O 操作的性能。
- 支持多种操作:io_uring 不仅支持传统的 read、write 等文件操作,还支持 accept、connect、sendmsg、recvmsg 等网络操作,甚至可以执行 epoll、poll 以及 fcntl、close 等操作。随着内核版本更新,越来越多的系统调用可以通过 io_uring 进行异步处理。
- 链接与依赖管理:io_uring 支持操作链接(linked operations)和依赖管理,这意味着可以将一系列系统调用按顺序提交,并根据前一个操作的结果决定是否执行下一个。这种机制可以实现复杂的异步控制流。
基于上述特性,可以设计出几乎完全基于 io_uring 的异步模型,将绝大多数系统调用实现为异步操作。可以显著减少阻塞等待的时间、减少上下文切换来提升性能。
局限性
- CPU 密集型系统调用:某些CPU密集型的系统调用(如计算型操作)并不适合 io_uring,因为异步模型对它们帮助有限。
- 有限的支持操作:虽然 io_uring 正在逐步支持更多操作,但某些系统调用仍暂时不支持异步化。
- 代码复杂性:io_uring 的使用通常比传统同步编程模式更复杂,因此实现全异步系统调用可能需要更多的开发成本和复杂的错误处理逻辑。
参考文章
- 一文让你透彻理解 SOCKET 编程:https://zhuanlan.zhihu.com/p/180556309
- 从内核角度看I/O模型:https://mp.weixin.qq.com/s/zAh1yD5IfwuoYdrZ1tGf5Q
- 拆解 Linux 网络包发送过程:https://mp.weixin.qq.com/s/wThfD9th9e_-YGHJJ3HXNQ
- Linux 异步 I/O 框架 io_uring:https://arthurchiao.art/blog/intro-to-io-uring-zh/
- 新一代异步 I/O框架 io_uring:https://mp.weixin.qq.com/s/7Z5ZE4pL258qHuEqRmS_tA
- epoll 与 io_uring 服务器编程实践及对比:https://juejin.cn/post/7074212680071905311
- 浅析开源项目之io_uring:https://zhuanlan.zhihu.com/p/361955546
- 我们为什么会需要 io_uring:https://www.byteisland.com/io_uring(1)-我们为什么会需要-io_uring/
- 从创建必要的文件描述符 fd 开始:https://www.byteisland.com/io_uring(2)-从创建必要的文件描述符-fd-开始/
- io_uring 的接口与实现:https://zhuanlan.zhihu.com/p/380726590
- io_uring 的实现原理与案例分析:https://mp.weixin.qq.com/s/ou8PHhDc3LZ9VII211yRUQ
- 关于 io_uring 性能测试:https://mp.weixin.qq.com/s/hTUpvsaMt4gd1ddrXuvE_g
- io_uring 与高性能网络 I/O 框架 Netpoll 的邂逅:https://mp.weixin.qq.com/s/QKppTm5j2202qYhpLifc0g
- io_uring 来了 !!:https://mp.weixin.qq.com/s/kaxjfhcbGW5wP442QyWPSg
- io_uring 设计与实现(一):https://zhuanlan.zhihu.com/p/334658432
- io_uring 设计与实现(二):https://zhuanlan.zhihu.com/p/334763504
- Windows 下 IOCP 的简单使用:https://zhuanlan.zhihu.com/p/544666070
- TCP 协议栈和内核旁路的选择? :https://www.cnblogs.com/huangfuyuan/p/9238437.html